
獨立樣本t檢定用於比較兩樣本的平均數是否有顯著差異,以下為其公式、使用方法及SPSS操作。
一、使用狀況
Two sample t-test:比較兩組樣本的平均值是否有差異。
例如:分析使用A牌飼料與B牌飼料餵養的乳牛,其每季平均生產的鮮乳量是否有差異。
二、前提假設
1. 依變數(Dependent variable):
◆必須是 連續變數(continuous variable)
◆必須為 隨機樣本(Random variable)→從母群體(Population)中隨機抽樣得到
2. 依變數的母群體:必須是常態分佈(Normal Distribution)
3. 獨立事件(Independent event):樣本須為獨立變項(Independent variable)→第一組的樣本不影響第二組的樣本;第二組的樣本也不影響第一組。
例如:分析從日本、美國兩地進口的蘋果甜度是否有差異,從日本進口與從美國進口這兩組樣本量測不會互相影響
4. 變異數(Variance):兩組樣本的變異數需為常態分佈,且符合變異數同質性。
【小常識】
無母數分析→1.依變數不是連續數時
2.依變數項母群體不是常態分布時
成對T檢定→當樣本不是獨立事件時
三、假說檢定(Hypothesis Testing)
獨立樣本t檢定(Two sample t-test):檢測兩組樣本的平均值是否不同 (常用)
虛無假說(Null hypothesis)→H0: u1(第一組平均數)=u2(第二組平均數)
對立假說(alternative hypothesis)→H1: u1不等於u2
本文例題主要以兩獨立樣本t檢定為主
四、SPSS 獨立樣本t檢定操作範例 Example
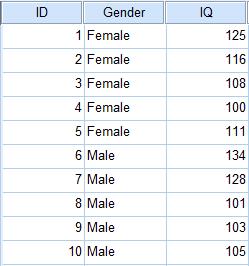
【例題】分析相同年齡的大學新鮮人中,男性(Male)與女性(Female)的智商(IQ)是否有差異?
本題的例子為兩組比較,故選擇Two sample t-test檢測兩組樣本的平均值是否不同
虛無假說(Null hypothesis)→男性與女性之間IQ無差異
對立假說(alternative hypothesis)→男性與女性之間IQ有差異
(一) 在SPSS中輸入欲分析之資料。
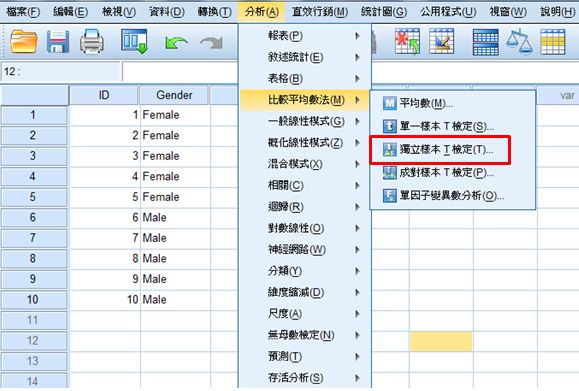
(二) Two sample t-test:分析→比較平均數法→獨立樣本T檢定
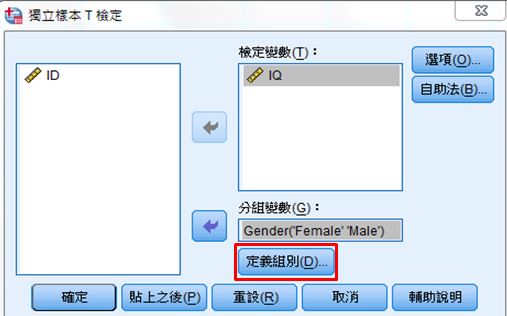
(三)檢定變數:智商(IQ)
分組變數:性別(Gender)
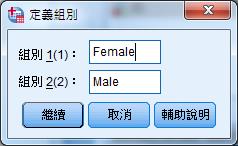
定義組別:組別1 Female、組別2 Male
(四) 檢定結果:
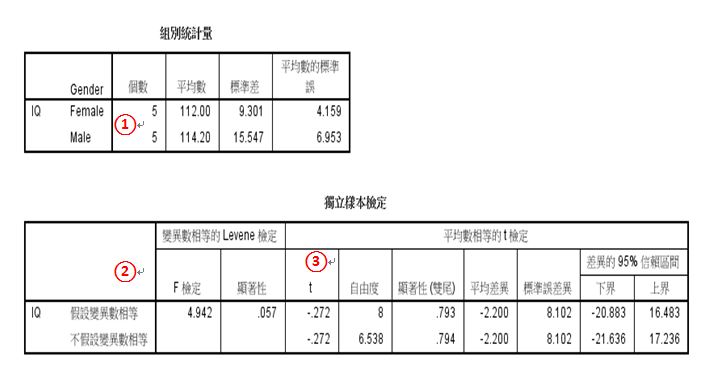
◆基本描述性統計:
分別有5位女性與5位男性包含在本次分析中。
女性的智商(IQ)平均為112.00,標準差為9.301
男性的智商(IQ)平均為114.20,標準差為15.547
◆兩組樣本變異數相等 (Levene檢定):
在本例中,F檢定後的結果,顯著性p值=0.057>0.05,兩組變異數並無顯著差異,所以屬於第一列(假設變異數相等);反之,若p值<0.05則代表兩組變異數有顯著性差異,需要修正T統計值,故要看第二列(不假設變異數相等)的結果。
◆平均數相等T檢定:
在本例中,計算後的t統計值為-0.272,雙尾顯著性p值=0.793>0.05,無法拒絕虛無假說。
→相同年齡的大學新鮮人中,男性(Male)與女性(Female)的智商(IQ)沒有顯著差異。
SPSS範例資料可從以下連結下載,僅供同學練習使用:
五、R 獨立樣本t檢定操作範例 Example
## Default
t.test(x, y = NULL,
alternative = c(“two.sided”, “less”, “greater”),
mu = 0, paired = FALSE, var.equal = FALSE,
conf.level = 0.95, …)
【語法說明】
1. 虛無假設:
One Sample t-test:單一樣本T檢定
## one sample t-test
t.test(x,mu=3) # Ho: mu=3
Two sample t-test:分析→比較平均數法→獨立樣本T檢定
## Independent 2-group t-test
t.test(x,y) # Ho: y1=y2, where y1 and y2 are numeric
2. alternative:選擇對立假說模式
雙尾→”two.sided”、單尾(>)→”greater”、單尾(<)→”less”
t.test(x,y, alternative=”greater”)
3. mu:選擇平均數(μ)
t.test(x,mu=3)
4. paired:若兩組樣本不是獨立事件時,需使用成對T檢定時改為TRUE
t.test(x,y, paired=T)
5. var.equal:假設兩組變異數不相等,若兩組變異數相等時改為TRUE
t.test(x,y, var.equal=T)
6. conf,level:結果顯示為95%信賴區間的上下界。
將結果改為顯示99%信賴區間的上下界→
t.test(x,y, conf.level=0.99)
【例題】分析非吸菸者(nonsmokers)的認知測驗分數是否較吸菸者(smokers)高?
本題的例子為兩組比較,故選擇Two sample t-test檢測兩組樣本的平均值是否不同
→輸入非吸菸者(nonsmokers)與吸菸者(smokers)的認知測驗分數
nonsmokers = c(18,22,21,17,20,17,23,20,22,21)
smokers = c(16,20,14,21,20,18,13,15,17,21)
→使用對立假說模式單尾(>),假設兩組變異數相等
t.test(nonsmokers, smokers, alternative=”greater”, var.equal=T)
輸出的結果為:
Two Sample t-test
data: nonsmokers and smokers
t = 2.2573, df = 18, p-value = 0.01833
→結果顯示T檢定值=2.2573,顯著性p值=0.01833<0.05,表示抽菸者與非抽菸者認知測驗分數顯著不同。
封面圖-500x383.png)



{kind=link}