
皮爾森(Pearson)相關分析主要用於探討兩變數之間的線性關係,其值介於-1~1之間,本篇文章主要介紹R語言中的操作,細節如下所述。
#補充1:Pearson相關性分析又被稱為Pearson積差相關係數、皮爾森相關分析、Pearson相關係數、或皮爾森相關係數。
#補充2:皮爾森相關分析的SPSS操作相關說明可參考以下網址:
https://www.yongxi-stat.com/pearson-correlation/
一、適用條件
使用皮爾森相關係數,需要滿足4個條件:
條件1. 變數類型為連續變數,例如:身高、體重、胸圍。
條件2. 兩變數之間為線性關係,可以用散佈圖來檢驗。
條件3. 兩變數沒有明顯的離群值,可以用箱型圖來檢驗。
#補充:Outlier(異常值或離群值):超過最小值(Q3+1.5 IQR)或最大值(Q1-1.5 IQR)的數值。
條件4. 兩變數要是常態分配,可以用分位圖或進行常態性檢驗。
二、R語言操作範例
(一) 資料匯入
score<-read.csv(“Score.csv”,header=T)
# read.csv ():將資料匯入到指定的變數,也就是score
View(score)
# View():瀏覽資料內容
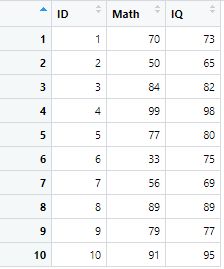
資料中ID為學生編號、Math為數學成績、IQ為學生智商分數。
attach(score)
# attach():可直接使用score裡面的所有變數,如Math, IQ。
(二) 適用條件判定
本範例的數學成績和學生智商分數的相關性,兩變數都是連續變數,滿足適用條件1「變數類型為連續變數」。
- 線性關係檢測
這裡的檢測方式採用散佈圖,用來判別資料之間,是否有相關聯性
#補充:散佈圖(Scatter Plot)
是表示兩個變數之間關係的圖,又稱相關圖。
依下列(A)~(F)的判斷方式,檢視是否為不相關。
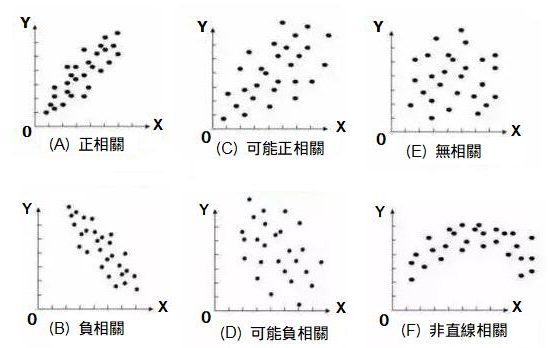
圖1 散佈圖的判斷方式
對數學成績和學生智商分數繪製散佈圖:
plot(IQ, Math) # plot():散佈圖
abline( lm(Math~IQ, data=score), col=”red”)
# abline():給圖形增加趨勢線
# lm(應變數(通常用Y來表示)~自變數(通常用X來表示), 資料來源):建構線性回歸模型
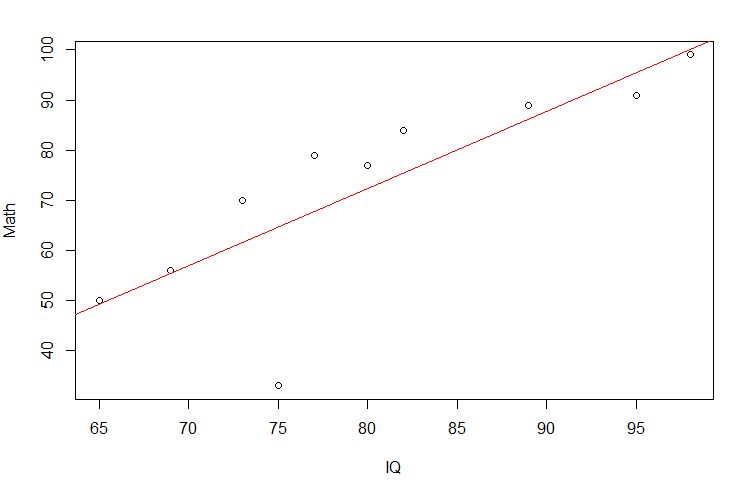
圖2 Math和IQ的散佈圖
如圖2所示,可見數學成績和學生智商分數呈線性相關(正相關),滿足適用條件2「兩變數之間為線性關係」。
- 離群值檢測
這裡的檢測方式採用箱型圖,來判別資料內是否存在離群值。
#補充:箱型圖(Box plot)
主要是用來顯示數據分佈情況。其組成要素為最小值、第一四分位數、中位數、第三四分位數以及最大值。
箱型圖能夠顯示出離群值(outlier),離群值也叫做異常值,通過箱型圖能夠很容易識別出資料中的異常值。
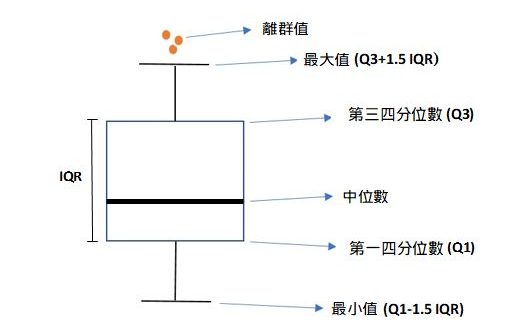
圖3 箱型圖
對數學成績和學生智商分數繪製箱型圖:
par(mfrow = c(1, 2)) #繪製一行2個圖片
boxplot(IQ, main = “IQ”) #繪製IQ箱型圖
boxplot (Math, main = “Math”) #繪製Math箱型圖
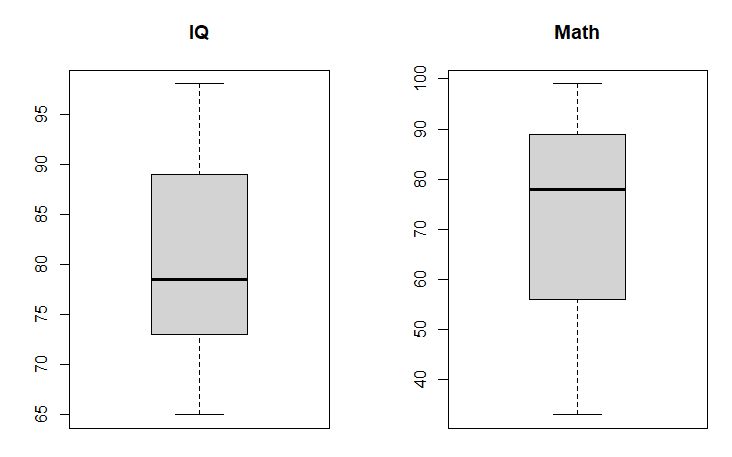
圖4 箱型圖(IQ和Math)
如圖4所示,數學成績和學生智商分數無明顯異常值,滿足適用條件3「兩變數沒有明顯的異常值」。
- 常態性檢測
這裡的檢測方式採用分位圖(Q-Q圖)和Shapiro-Wilk檢定來做是否為常態分配。
#補充:分位圖(Q-Q圖)
是一種視覺化比較兩項數據的分佈是否相同的方法。
另外,Q-Q Plot不是只有判斷「是否為直線」或者「是否為常態分配」,即使畫出來的不是直線,還是能看出資料分配的特性。
從圖7中可以看到Q-Q Plot在左偏與右偏分配會呈現的樣子:
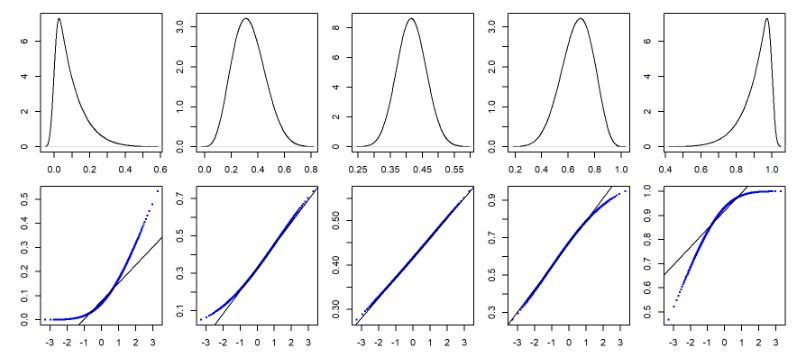
圖5 不同數值分配下的不同 Q-Q Plot(Source: Manny Gimond)
(1) 對數學成績和學生智商分數繪製Q-Q圖:
qqnorm(IQ, main = “QQ plot”, col = “blue”, ylab = “IQ”)
# qqnorm( 繪製圖形的變數, 圖形標題, 設置顏色, 設置y軸標籤)
qqline(IQ, col = “burlywood”, lwd = 2)
# qqline(設置輔助線, 設置顏色, 設置線寬)
grid(lty = “dotted”, col = “gray75”)
# grid(設置網格, 設置顏色)
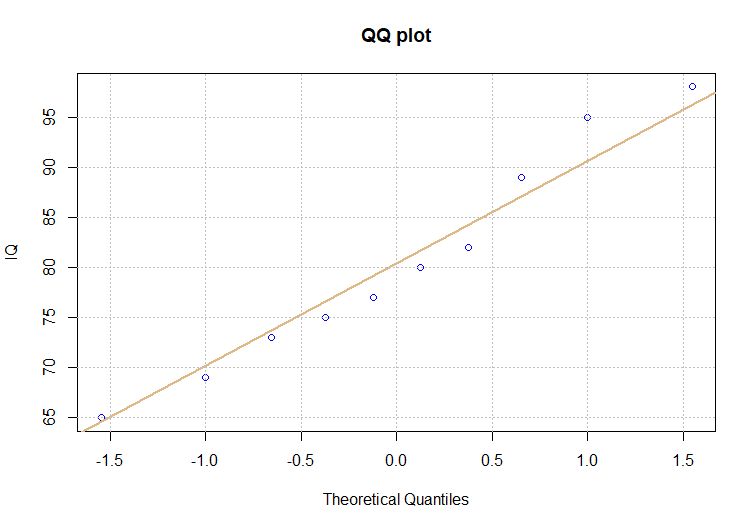
圖6 學生IQ的Q-Q圖
qqnorm(Math, main = “QQ plot”, col = “blue”, ylab = “Math”)
qqline(Math, col = “burlywood”, lwd = 2)
grid(lty = “dotted”, col = “gray75”)
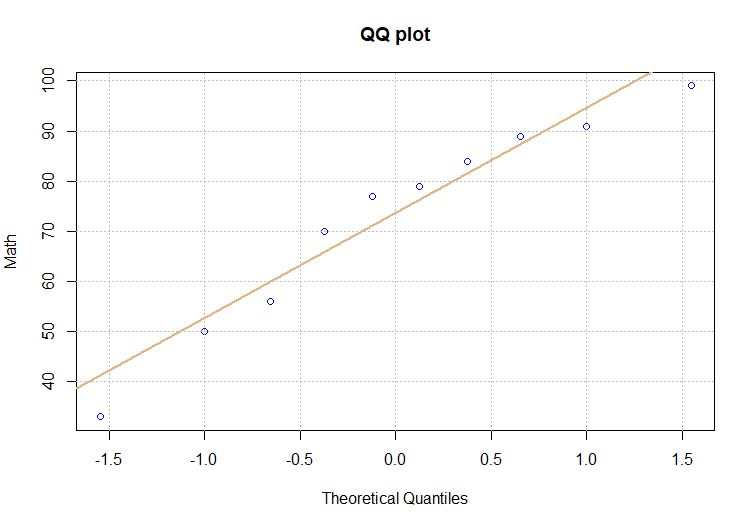
圖7 數學成績的Q-Q圖
根據圖6和圖7的分析結果顯示:數學成績(Math)和學生智商分數(IQ)呈常態分配。
#補充:使用Shapiro-Wilk檢定的原因
要進行常態性檢定有兩種方法K-S檢定或S-W檢定,因樣本數的關係而選擇使用S-W檢定。
Kolmogorov-Smirnov(K-S)檢定:樣本數50個以上。
Shapiro-Wilk(S-W)檢定:樣本數50個以下。
(2) 對數學成績和學生智商分數做常態性檢驗:
shapiro.test(IQ) #檢驗IQ的常態性
shapiro.test(Math) #檢驗Math的常態性
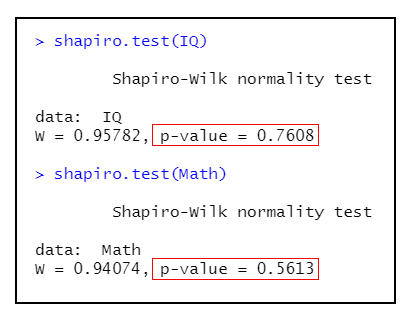
圖8 S-W檢定(IQ和Math)
根據圖8的分析結果顯示:兩變數的常態性檢驗的P值均>0.001,滿足常態性要求。
結合(1)(2)的結果,表示兩變數的資料滿足適用條件4「兩變數為常態分配」。
結論,本案例的資料滿足Pearson相關性分析的4個適用條件。
(三) Pearson相關性分析計算
方法一:cor()
cor(IQ, Math)

方法二:cor.test()
cor.test(IQ, Math, alternative=”two.side”, method=”pearson”, conf.level=0.95)
# cor.test(x, y, //檢驗的變數
alternative = c(“two.sided”, “less”, “greater”),
// alternative為顯著性檢定:雙尾(two.sided)、單尾(less:相關性<0,左側)(greater:相關性>0,右側)
method = c(“pearson”, “kendall”, “spearman”), //method為檢驗的方法
conf.level = 0.95, …) //conf.level為檢驗的信賴區間的信心水準
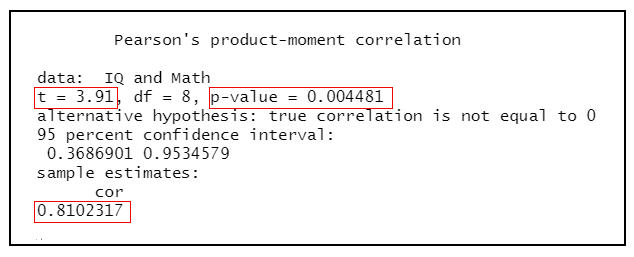
根據分析結果顯示:數學成績和學生智商分數是有相關性。
Pearson相關係數r=0.810,統計檢定量t=3.91,顯著性p值=0.004<0.001,拒絕虛無假設(ρ=0),接受對立假說(ρ≠0),兩變數間呈高度相關。
四、結論
本研究採用Pearson相關性分析對學生智商分數(IQ)和數學成績(Math)的相關性進行了檢驗,
透過散佈圖顯示兩變數之間呈線性關係、箱型圖顯示兩變數的資料無異常值、Q-Q圖和Shapiro-Wilk檢驗顯示資料為常態分佈。
Pearson相關性分析結果顯示,IQ和數學成績之間為正相關(r=0.810,P<0.001),IQ越高的人,數學成績也會越高,相關性程度較強。
封面圖-500x383.png)


