
R語言之所以越來越多人使用,除了界面簡單易學,更是因為R能做得事情相當多,而能夠支撐R語言擁有這麼多統計分析功能,就是Package,也就是套件(或稱作R包),幾乎所有問題都能夠在R package找到解決辦法!而在超過萬個package中,我們將介紹幾個相當好用,可以說是必學的幾個套件給大家:
一、初始 package
- base : 基礎函數
- datasets : 內建數據集合
- graphics : 基礎繪圖工具
- grDevices : 基礎繪圖介面
- methods : 定義class of objects
- ststs : 基礎統計分析
- utils : 基礎程式撰寫工具
以上7大套件是進入R語言後他會自動就安裝並執行好的套件,但他所能提供的就是最基礎的功能,因此使用起來不算太實用,大家可以就看看即可。通常我們不管是要做繪圖、統計或者是資料清洗,單靠這些基礎套件是不夠的,還是需要透過安裝更多元功能的新套件。
二、如何安裝與載入 package
(一)安裝package
首先我們必須先將想要的套件安裝好,那麼我們其實有兩個方式可以去執行安裝動作,第一個就是用點選的,也是最直觀的,而另一個則是我們自己輸入程式碼去執行,那麼就看大家使用起來覺得哪個最順手就用哪個囉~
1.點選方式
Step1: 首先在我們R Studio右下角那個區塊找到Packages

Step2:再來點選Install,點選後會出現以下畫面,並專注在package中間這個格子裡。
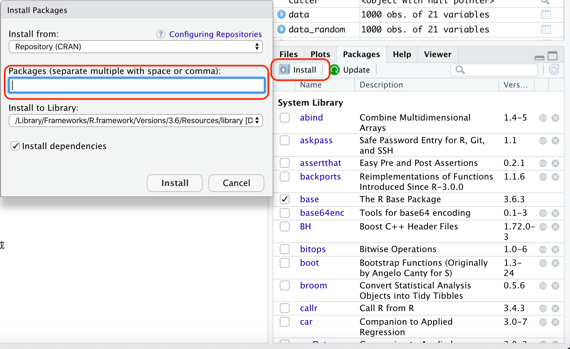
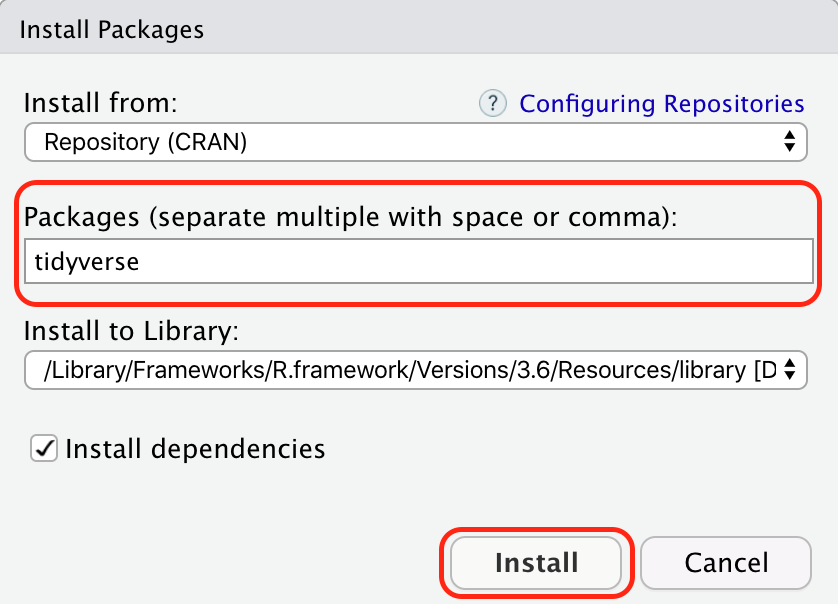
Step3:接著呢,只要輸入想要安裝的套件並且按下右下install即安裝完成!這裡就以tidyverse套件來做示範。

2.輸入程式碼
接下來是直接輸入程式碼方式,也是我個人偏好使用的方式,因爲只需要一個動作就完成!
install.packages(“tidyverse”)
我們只要在workspace地方打上install.packages而括號內輸入套件名稱即可,這裡要特別注意不要忘了加上引號,那大家是否也覺得這個方法比較快速呢?
(二)載入package
而在安裝好套件之後,很多使用者都會忘記還要載入其安裝後的套件,載入套件是必要的,不然會無法執行其功能喔。那載入套件和安裝套件一樣,也有兩種方法。
1.點選方式
Step1: 首先在我們一樣在R Studio右下角那個區塊找到Packages

Step2:再來,可以在下方的套件列表中,找到剛剛安裝完成的套件

Step3:接著呢,只要點選打勾套件名稱旁邊的小格子即完成載入
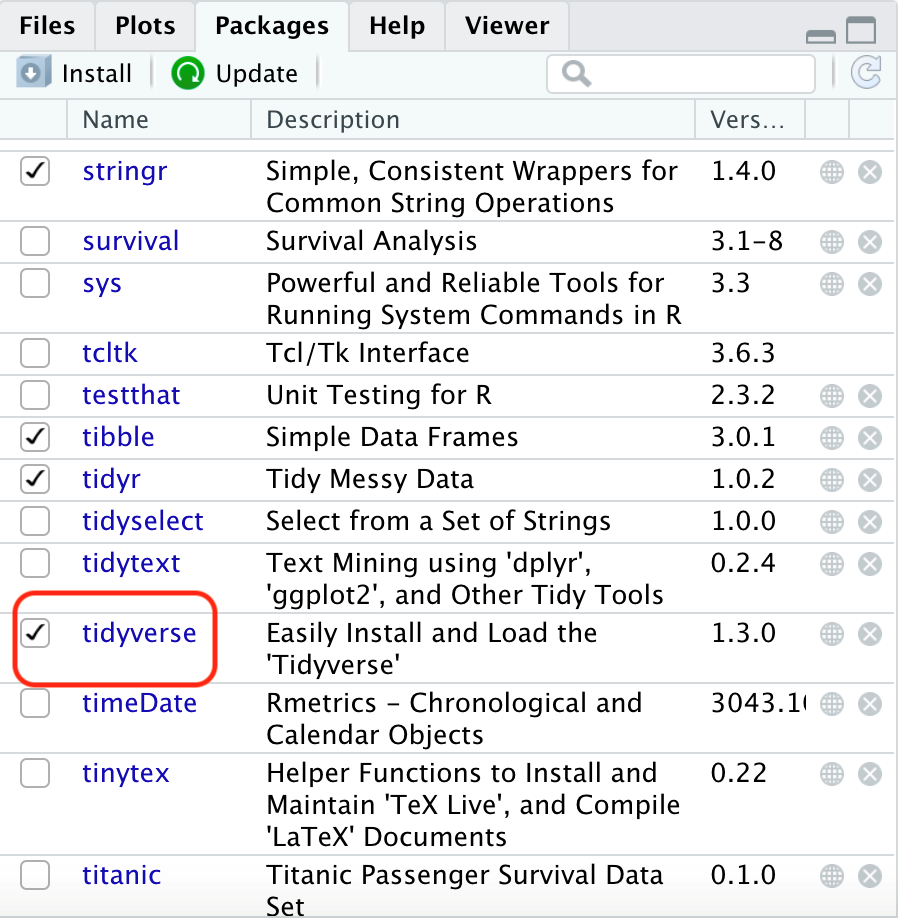

2.輸入程式碼
接著如同安裝套件一樣,我們同樣可以利用一段程式碼就呼叫載入套件完成,而是使用library()來載入。
library(“tidyverse”)
以上就是安裝以及載入套件的流程,其實兩種方式都很簡單,同學們可以依照自己覺得順手的方式做就可以了,而輸入程式碼的方式還有個優點是,你可以比較快速回頭檢視自己是哪個套件忘記安裝以及載入喔。
三、推薦 package
那麼這裡也想推薦幾個非常非常實用的套件給大家,大家有空可以自己玩看看這些套件的各種特殊且有趣功能。而在後面章節的課程,也會常使用到這些套件!
(一)ggplot2
1.簡介:
第一個要推薦給大家的就是一個大家公認最強的繪圖套件ggplot2,而它其實是R語言第三個繪圖套件了,但是它的功能以及實用性實在是太高了,以下會有範例給大家參考,而此套件功能目前還持續更新中,因此大家可以在其網站GITHUB多多關注。
2.核心元素:
- aes (Aesthetic attributes) :主要內容為點的大小、顏色、線的粗細
- geom (Geometric objects):主要內容為圖型,包括盒狀圖、長條圖
- facets:主要是讓一張圖內顯示多張子圖
- scales:主要修飾點線顏色、xy軸定義等
- stat:統計方法
而ggplot2套件主要就是圍繞在這五個元素下去做組合,當然還有其他有趣的元素被更新出來,大家可以去試試,以下用一些範例來呈現ggplot2繪圖成果。
3.範例:
ggplot(data,aes(x=months_loan_duration,y=amount)) +
geom_point(size = 0.8, alpha = 0.4, #size點的大小
color = data$default) +
stat_smooth(method = “auto”,se = T, size = 0.5) + #回歸#SE顯示標準差
scale_color_brewer(palette = “Dark2”) + #調色板
scale_shape_manual(values = c(2,3)) #點的形狀
上面程式碼,欲在一資料集合(信貸紀錄)中,找到“貸款金額”和“貸款期限”之間的關聯性,因此我希望以統計迴歸的方式呈現,另外調整一些比較視覺化的設定。可以看下圖呈現結果,可看出“貸款金額”和“貸款期限”呈現正相關。
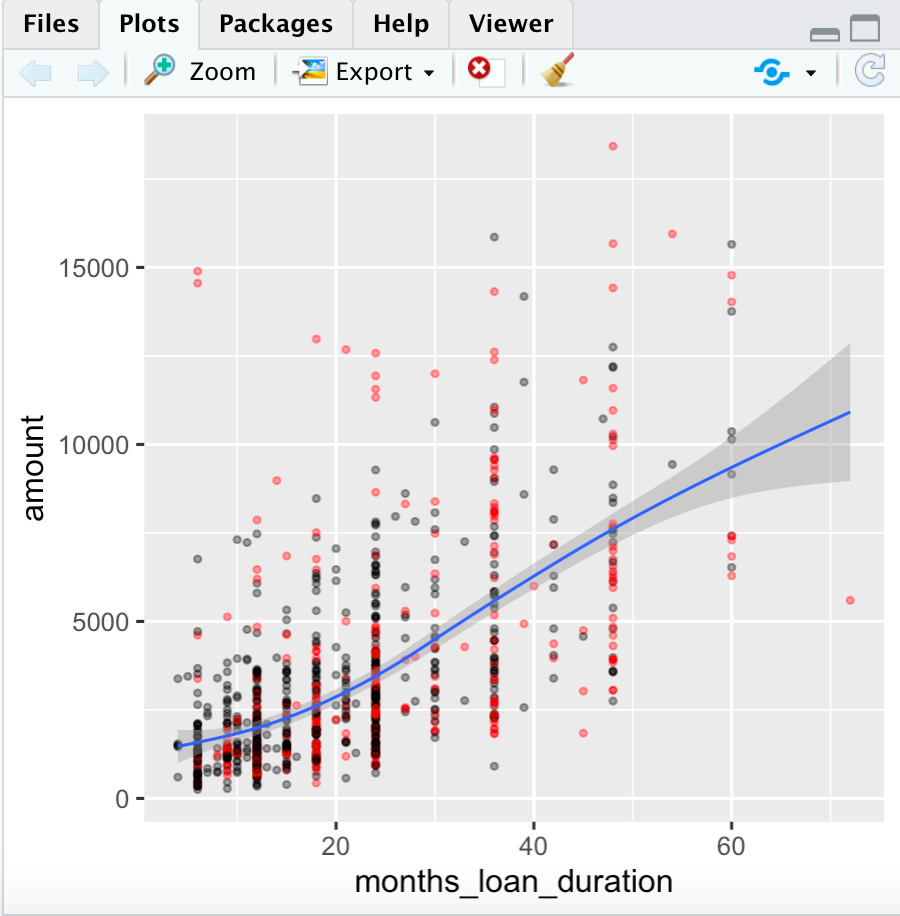
圖形會呈現在右下角區塊。
ggplot(data = mutate(data, default = as.factor(default)),
aes(x = credit_history, group = default)) +
geom_bar(aes(fill = default), position = “dodge”, stat = “count”) +
#fill按default填色 #position=”stack”,”dodge”
scale_fill_manual(“default”, values = c(“1” = “skyblue”, “2” = “pink”)) + #將違約以藍色呈現、不違約以粉紅呈現
scale_x_discrete(limits = c(“critical”, “delayed”, “repaid”,”fully repaid”, “fully repaid this bank”)) #替x軸命名
接著同樣一資料集合,我希望透過長條圖來做分類,將“是否違約(default)”分為會違約以及不會違約,以及希望查看”過往信用紀錄(credit_history)“和“是否違約(default)”之間有何關係。
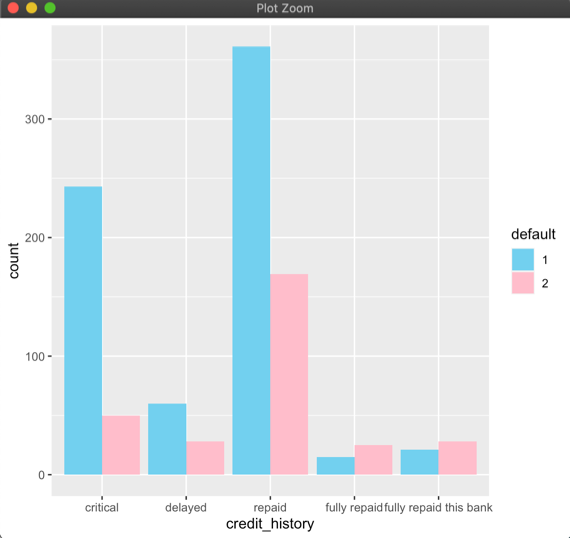
可以根據呈現出的結果判斷出,過往信用紀錄是準時償還貸款(“fully repaid”, “fully repaid this bank”)的違約比例較少,而總是遲繳或者缺繳(“critical”, “delayed”)的違約比例較高。
透過以上兩種圖型呈現的結果,是不是可以看出ggplot2的強大?現在不熟悉他的運作方式沒關係,未來有機會會出一篇資料視覺化呈現,到時再為大家完整講解使用方式。
(二)magrittr
1.簡介:
第二個要推薦給大家的是一個在執行多個函數時能夠快速且清楚列出程式碼的一個套件,若我們想要針對某資料集合或者某向量進行資料處理時,可能會利用多種函數,但若使用傳統輸入方式可能會容易搞混或者不好檢查,因此透過應用 %>% 此運算子,就能簡化該程式碼。
2.範例:
假若今天我們想針對我們之前建立的資料框(dataframe_sample)進行檢查結構時str() ,將不會是我們之前使用的傳統方式,看以下程式碼範例。
str(dataframe_sample) #傳統呼叫函數方式
dataframe_sample %>%
str() # %>%管線運算子
可以看出,不同於以往方式,在使用%>%方式時,我們會將函數移至最右邊,結果顯示會是一樣的。

而這樣的範例可能還顯示不出使用%>%的實際好處,現在就用一個需要使用多次函數的範例示範給大家看,假設今天我想要將此資料結合的“年齡”變數獨立拉出來做描述性統計,可以參考以下兩種比對做法:
# 最傳統寫法
dataframe_sample_age <- select(dataframe_sample,”age”)
summary(dataframe_sample_age)
# %>%管線運算子
dataframe_sample %>%
select(“age”) %>%
summary()

兩種做法都能得到以上呈現之結果,但是我們使用%>%管線運算子,卻可以省略“ dataframe_sample_age ” 此中介物,除非此中介物是後續操作會使用到的,否則能省略當然省略囉!
*小補充:可以使用快捷鍵 Ctrl+ shift + M 快速叫出%>%喔!
(三)dplyr
1.簡介:
最後一個要推薦給R初心者的套件就是dplyr,dplyr是一個整理資料相當好用的套件,許多重要功能讓整理資料變得輕鬆且容易,使用上若能搭配%>%使用會更有效率。
2.核心函數:
- filter() :主要為篩選預定條件之觀測數值
- select():主要為挑選選定之變數
- mutate():主要為新增變數
- summarise():主要為聚合變數
- group_by():主要為類別變數進行排序
- arrange():主要為依各個變數排序觀察值
以下會以幾個範例來呈現這些函數主要功能,讓我們繼續看下去吧~~
3.範例: 以“ dataframe_sample” 資料框為範例

#欲挑選出購買A1產品之顧客
P_A1 <- dataframe_sample %>%
filter(purchase_item == ‘A1’ )
P_A1
#欲挑選出付款方式之變數
Payment <- dataframe_sample %>%
select(payment_method)
Payment


首先是想挑出挑選出購買A1產品之顧客和挑選付款方式之變數,可以看到挑選是不是更方便閱讀了呢?!
#欲新增一變數在原資料集合
new_data_sample<- dataframe_sample %>%
mutate(
marital = c(‘married’,’single’,’married’,’married’,’single’,’single’,’single’,’single’)
)
new_data_sample

今想要新增是否已婚之變數進原資料框裡,用mutate() 相當快速。
#欲將資料集合以年齡變數進行排序
AGE_data_arrange <- dataframe_sample %>%
arrange(age)
AGE_data_arrange
#欲計算年齡變數之平均數
MeanAGE <- dataframe_sample %>%
summarise(mean(age))
MeanAGE
#欲計算男性和女性顧客分別之年齡平均數
FMeanAge <- dataframe_sample %>%
group_by(gender) %>%
summarise(mean(age))
FMeanAge

![]()

以上就是dplyr套件中6大函數的使用範例囉~同學們可以自己動手製作一個資料框來練習看看,其實過程相當有趣的!那在後面章節也會有更完整的資料結構處理和資料清洗的介紹帶給大家。
*小結:其實以上3個推薦入門的套件呢,其中兩個ggplot2和dplyr是包含在一個叫做Tidyverse的大套件之中。而Tidyverse就好像一個大家庭,其中就包括以上兩個套件和其他tidyr、readr、purrr和tibble套件,可以看做是一個完整的系統,集結多元功能。
而由於是包含在Tidyverse套件之間,因此當我們載入Tidyverse套件時,就可以同時載入以上六大套件囉。
封面圖-500x383.png)


