
傾向性評分匹配主要是在隨機對照實驗(Randomized controlled trials, RCT)中,用來測量實驗組與對照組樣本的其他各項特徵(如性別、年齡、身高、體重、種族…等)在整體均衡性上的分組考量。
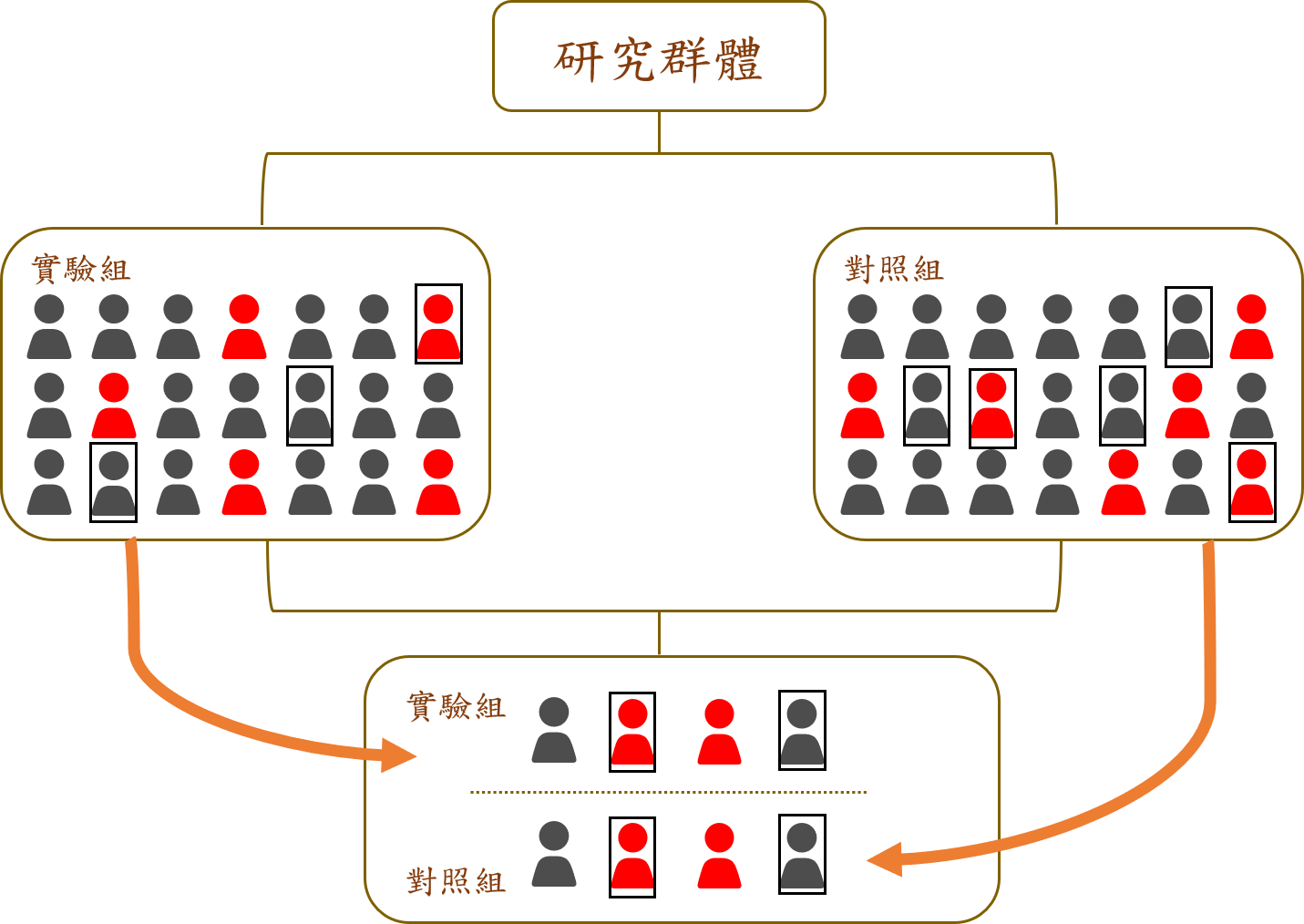
舉例來說,若研究某種藥物對疾病的影響,在臨床實驗中,實驗組與對照組應除了使用藥物/安慰劑有所差異外,其他的臨床特徵(如性別、年齡等)都應該基本相似,如此才能觀察實驗組與對照組在藥物使用與否上的差異,進而驗證藥品的有效性。
一、適用情形
傾向性評分匹配適用於以下兩種情形:
1. 在研究中,實驗組與對照組可直接比較的個體數量很少,若直接將兩者進行比對,容易產生非常偏倚的結果。
2. 在研究中,當衡量個體特徵的變數很多時,若想要從對照組中找出一組各項變數都與實驗組相同或相近的子集便會變得非常困難。
當遇到上述兩種情況時,便可使用傾向性評分匹配,藉由邏輯迴歸模型來決定各實驗組與對照組的評分。
二、傾向性評分匹配的步驟
1. 計算傾向值(使用邏輯迴歸)
2. 進行得分匹配,主要可歸類於以下三種方法
(1) 最鄰近匹配(Nearest neighbor matching, NNM):以傾向得分為依據,在對照組中尋找一個或多個與傾向值相同或相近的樣本作為配對對象,在本次的SPSS範例中便採用此種方法。
(2) 半徑匹配(Radius matching):設定一個常數R(為一個區間,一般為小於傾向得分標準差的四分之一),並將實驗組得分值與對照組得分值的差異在R內的進行配對。
(3) 核匹配(Kernel Matching):傾向性評分匹配與核匹配結合後可以通過加權評分增加個別較重要變數的權重,而權重數可由核函數計算得出。
三、SPSS 操作Example
**在SPSS 19版以後,便可以用外掛方式在SPSS中使用PSM功能;在SPSS 21版以後,可以在功能表「資料」下使用「傾向分數對照」。
** 本文使用SPSS 25版進行分析。
【例題】某研究想要瞭解「喝酒」(設置「1」為喝酒;「0」為不喝酒)與「高血壓」之間的關係,打算使用某項調查資料抽取實驗組與對照組樣本,進一步觀察「喝酒」與「高血壓」之間的關聯。
(一) 在SPSS中輸入欲分析之資料。
(二)資料→傾向分數對照
(三)將變數根據需求進行配置
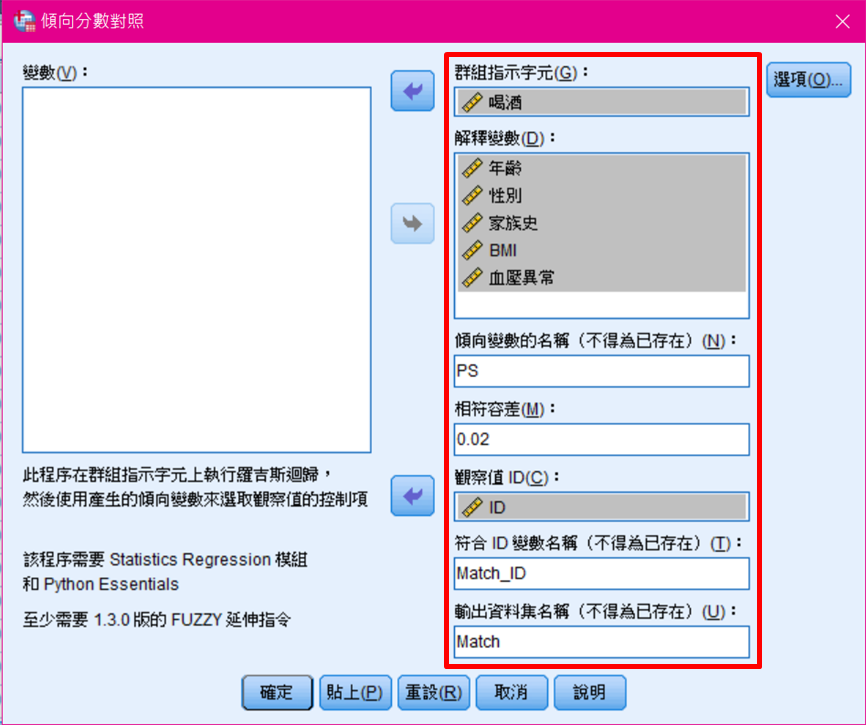
1. 將「群組指示字元」放入欲分組的變數,本研究分析的主題是將喝酒組與不喝酒組進行配對,因此放入「喝酒」。
2. 將「解釋變數」放入欲匹配的變數,如本研究希望以「年齡」、「性別」、「家族史」、「BMI」、「血壓」進行匹配。
3. 設定「傾向變數的名稱」,如本研究以「PS」作為代表。
4. 設定「相符容差」,此數值若設置的越小,則喝酒組與不喝酒組配對後的可比性會越高,但相對地也代表匹配難度會加大,本研究設置為「0.02」。建議大家可以先設定一個數值,再視匹配後的數量進行增減。
5. 設定「符合ID變數名稱」,如本研究以「Match_ID」作為代表。
6. 設定「輸出資料集名稱」,如本研究以「Match」作為代表。
(四)點選「選項」
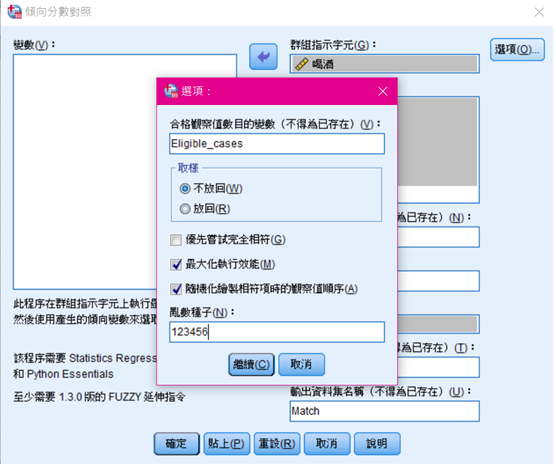
1. 設定「合格觀察值數目的變數」,如本研究以「Eligible_cases」作為代表。
2. 取樣默認為「不放回」。
3. 將「最大化執行效能」與「隨機化繪製相符項時的觀察值順序」打勾。
4. 「亂數種子」是指在匹配的過程中,若對照組有多筆對象同時滿足實驗組的觀察條件,則SPSS會隨機將其進行1:1的匹配。然而,由於每次SPSS操作時給的隨機值不同,若不進行設定,則每次配對的對象會是不一樣的,因此需要手動設置一個亂數,如本研究設置為「123456」。
(五) 報表結果:
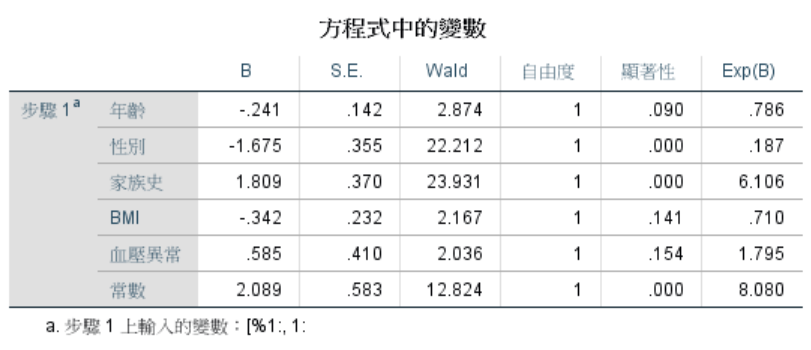
* 上表以「喝酒」(1為喝酒;0為不喝酒)作為應變數,其他需要調整的變數作為自變數建構迴歸模型,藉此能得出每一個觀察對象的PS值。
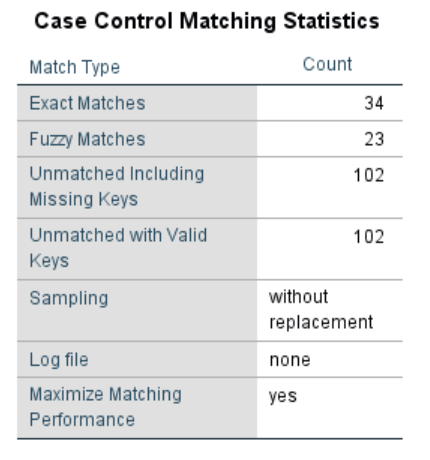
* 上表顯示「精準匹配」有34對,「模糊匹配」有23對,共匹配成功57對。
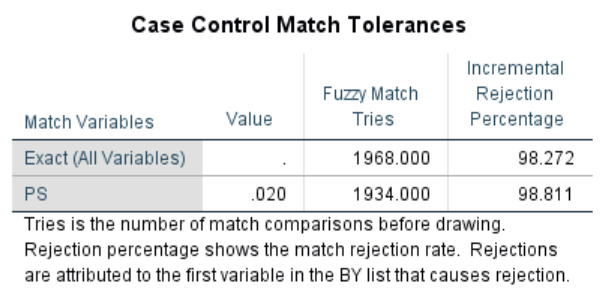
* 上表顯示了匹配過程,在「精準匹配」下匹配了1968次,約有1.728%匹配成功;接著再進行「模糊匹配」(即以當初設定的「相符容差」值0.02進行匹配),共匹配1934次,約有1.189%匹配成功。
(六)匹配後的檔案
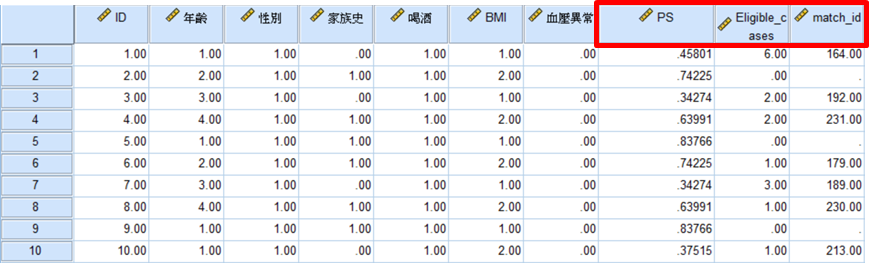
*輸出的資料庫會多了幾個之前設定的新變數,「PS」為使用上述迴歸模型計算出的傾向性評分;「Eligible_cases」表示對照組有幾個符合條件的觀察值對象;「Match_id」表示匹配成功的ID。
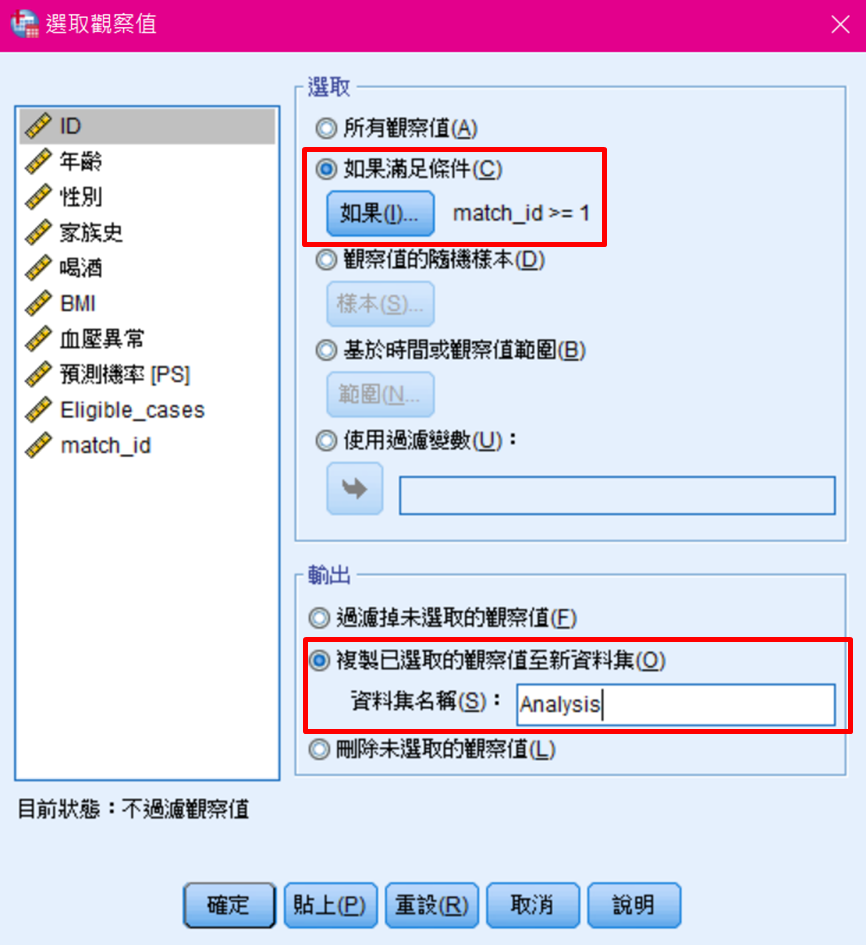
(七)檔案整理:資料→選取觀察值
1. 將「如果滿足條件」設置「match_id≥1」。
2. 設置一個新資料集的名稱:本研究將「複製已選取的觀察值至新資料集」的「資料集名稱」設置為「Analysis」。
(八)設置匹配成功的ID標示:轉換→計算變數
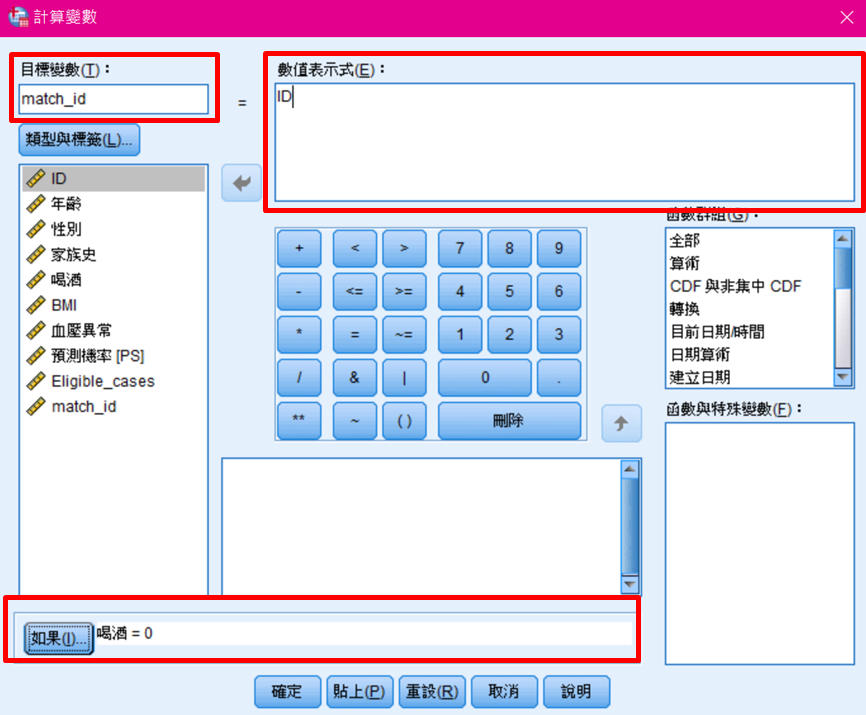
1. 將「目標變數」設置為「match_id」。
2. 將「數值表示式」設置為「ID」。
3. 將「如果」設置為「喝酒=0」。
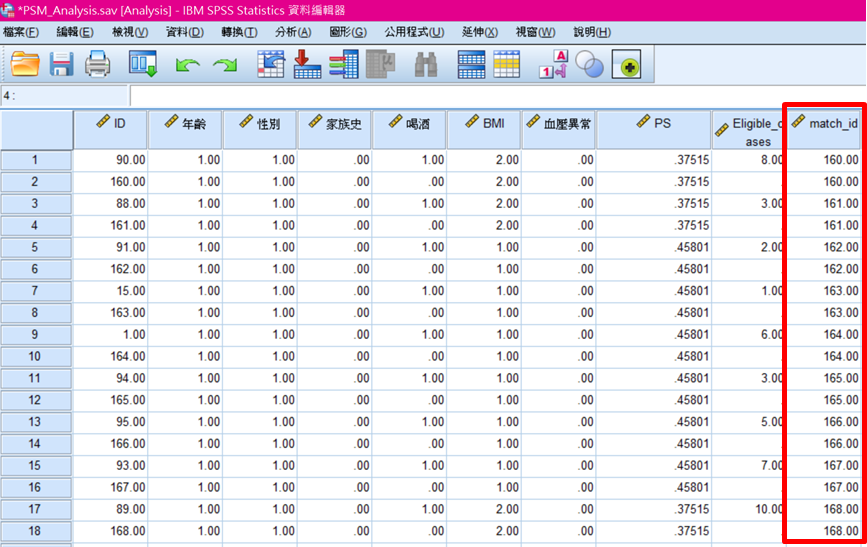
* 在「match_id」欄按滑鼠右鍵,選擇「遞增排序」
* 如此一來「match_id」便能看出兩兩配對成功的ID樣本,完成傾向性評分匹配。
封面圖-500x383.png)


