封面圖.png)
假設檢定(Hypothesis Testing)是一種統計方法,用來檢驗對一個或多個總體參數的主張是否成立。而統計假設檢定又可分為參數檢定(parametric test)和非參數檢定(nonparametric test),它們的區別主要在於是否對數據分佈做出了特定的假設。
參數檢定主要用於檢測數據是否符合特定模型或理論預測的情況,而非參數檢定並未對數據分佈做出任何特定的假設,因此非參數檢定可以應用於更廣泛的情況,尤其適合於處理不符合常態分佈或其他特定分佈的數據。
本文主要介紹如何使用計算套件scipy進行常態性檢查,細節說明參照如下。
1. python畫機率圖(probability-plot)
機率圖是一種通用的術語,可以指任何一種以機率為軸繪製的圖形。機率圖的目的是為了視覺化並比較數據的分佈。
例子:假設我們在健身房裡收集到所有會員的心率數據(次/分鐘),我們想要檢查這些心率數據是否符合常態分布。
# 導入需要的Python庫。
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
# 假設 data 是某健身房裡所有會員的心率數據,單位為次/分鐘。使用 numpy 的 random.normal 方法來生成一些符合常態分佈的隨機數據。
data = np.random.normal(loc=72, scale=10, size=100)
# 使用Scipy的probplot函數來生成圖。
stats.probplot(data, plot=plt)
# 設置圖的標題。
plt.title(‘Probplot – Heart Rate of Gym Members’)
# 顯示圖。
plt.show()
#執行後得到下列機率圖。
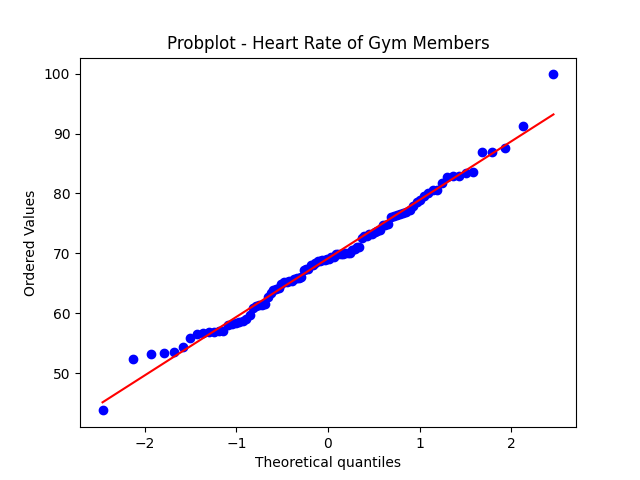
在這張圖中,藍點表示實際數據點,紅色的線表示理想的分佈,如果藍點大致上落在紅線附近,我們可以推斷數據接近於常態分佈。
2.python執行常態性檢定
常態性檢定用於檢驗一組數據是否來自或者可以被看做是來自一個常態分佈的群體,常態性檢定的目的在於瞭解你的數據是否足夠“正常”,以便可以使用基於這個假設的其他的統計檢驗。
例子:假設我們種植了一批果樹,現在想要知道樹的高度是否遵循常態分布,因為這會影響到灌溉、修剪以及採收策略。
# 導入需要的Python庫。
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
# 設置隨機種子以得到可重複的結果。
np.random.seed(0)
# 假設果樹的平均高度為5公尺,標準差為0.3公尺。我們有500棵果樹。
mean_height = 5
std_deviation = 0.3
num_trees = 500
# 隨機生成500棵果樹的高度,並進行同質性檢驗。
tree_heights = np.random.normal(mean_height, std_deviation, num_trees)
# 使用D’Agostino & Pearson test的檢定方法,用於檢查樣本數據是否偏離了常態分布。
k2, p = stats.normaltest(tree_heights)
print(“p = {:g}”.format(p))
# 如果p值大於0.05,我們假設高度分布是常態的。
if p > 0.05:
print(“樹的高度可能符合常態分布”)
else:
print(“樹的高度可能不符合常態分布”)
# 我們可以繪製一個直方圖來查看高度分布。
plt.hist(tree_heights, bins=20)
plt.show()
#執行後得到下列p值結論及直方圖。

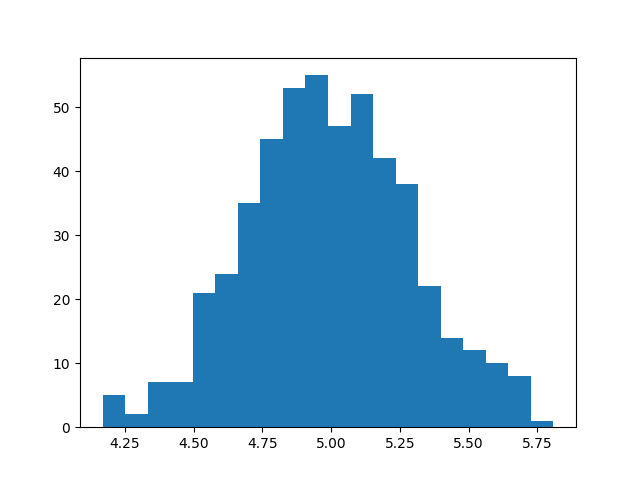
從這個直方圖我們可以看到果樹的高度分佈。
以上便是Python Scipy的機率圖與常態性檢定,若您覺得有幫助的話,再請幫我們留個好評,謝謝您的觀看,我們下次見。
封面圖-500x383.png)


