
混合線性模式主要用於分析有重複測量的資料,其概念建立在基礎的迴歸分析上面,使用上類似概化估計方程式(GEE),其特點是可以同時估計固定及隨機效果,適用於個人推估,主要說明如下。
一、使用狀況:
混合線性模式(LMM)最主要是使用在長期追蹤研究(Longitudinal studies),其變項在每次追蹤上有重複測量的狀況(例如:同一個病人去醫院看三次病,每一次的就醫紀錄或生物指標),變項每次量測之間互相不獨立,或研究架構為鑲嵌(例如:同一個醫生看了很多個病人,考慮醫生之間的差異)的研究。
名詞定義與解釋:
1. 固定效果(Fixed-effects):別人要來重複你的研究,則別人可以同樣的分類標準來分類,例如性別、年齡及教育程度,即推論是來自於目前的分類標準,通常就是研究中要探討的變項
2. 隨機效果(Random effects):許可別人有不同分類標準的變項,在重複量測中,通常個案即是random effects變項,代表允許每一位個案的初始值(在我們這個例子中,就是前測分數)可以不同
3. 混合線性模式(mixed-effects model):同時包含固定效果跟隨機效果,我們就稱為混合線性模式
4. 共變異數矩陣(covariance structure):用來解釋測量之間的關係,常見有四種:非結構化 (Unstructured)、簡易式(Simple)、複合對稱(Compound symmetry)、一階自迴歸模型(First-order autoregressive, AR(1))
1) 非結構化 (Unstructured):假設重複測量之間的相關性皆為不同,沒有規律。對重複測量間的相關結構沒有任何概念時,或是不想先行給定任何假設時可使用,但不易收斂。
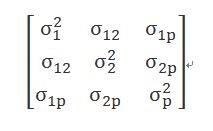
2) 簡易式(Simple):測量之間的相關性獨立,不適用於重複測量
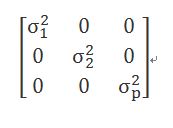
3) 複合對稱(Compound symmetry):假設重複測量之間的相關性都一樣。Repeated measurement ANOVA的前提假設就是如此。
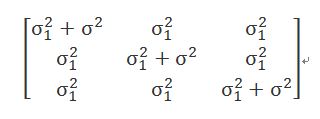
4) 一階自迴歸模型(First-order autoregressive, AR(1)):每筆資料和上一個量測有關。
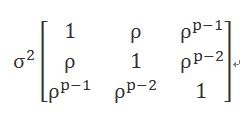
二、迴歸模型:
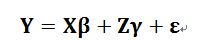
X跟Z分別為獨立變項矩陣
β代表固定效果(Fixed-effects)的常數向量
γ代表隨機效果(Random effects)的隨機向量
ε為誤差項
在混合線性模式之中,我們可以透過假設X跟Z共變異數矩陣以解釋重複測量之間的關係。
前提假設:
重複量測研究
(因為變項之間互相獨立的提假設被打破,故一般常用的統計模式不適合使用)。
與GEE的差異:
| Mixed effect Model | GEE |
| 應變項為連續變項 | 應變項為連續變項、序位及類別皆可 |
| 選錯correlation matrix 結果可能會差異很大,而且SE可 能會估計不出來 | 較為robust,故選錯correlation matrix,對結果影響較小 |
| 刪除遺漏值 | 保留遺漏值 |
| 用於個人推估 | 用於個人或族群推估 |
三、SPSS分析範例
1.在SPSS中輸入欲分析之資料。
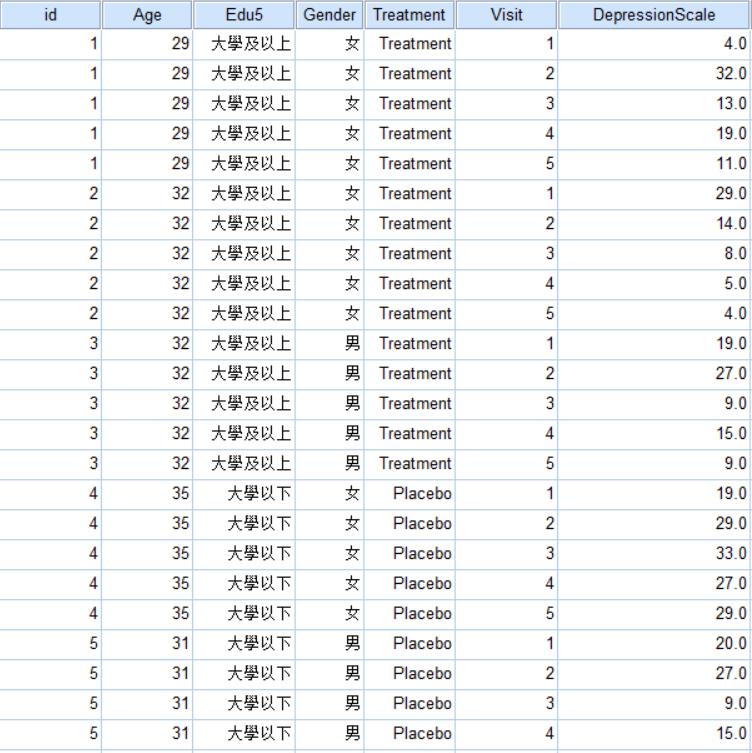
目前有20位憂鬱症病人分別使用藥物治療或安慰劑,我們追蹤了5次就診紀錄,獲得他們每次就醫時的憂鬱症分數,我們利用這筆資料,分析藥物對於憂鬱症的療效。資料建議要是Balance Data,有遺漏值則可能會有估計偏誤。
treatment表示介入的治療方式;Gender表示性別;Visit表示就診時間點;Depression表示憂鬱分數,分數越高憂鬱傾向越大。
2.分析→混合模式→線性
3. Mixed effect model
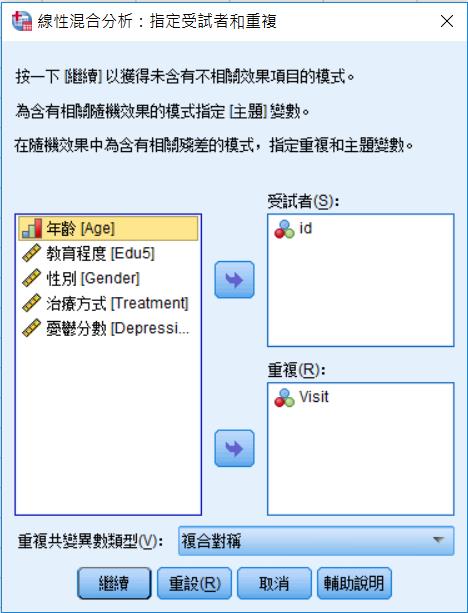
受試者變數:點選ID。
重複:選Visit。
重複共變數類型:可以先選非結構化。之後在透過AIC及BIC可以得知哪個是最好的共變結構假設,選數值越小越好。所以可以跑不同的共變結構假設後,選取AIC及BIC最小的當最後的模式。
【線性混合模式】
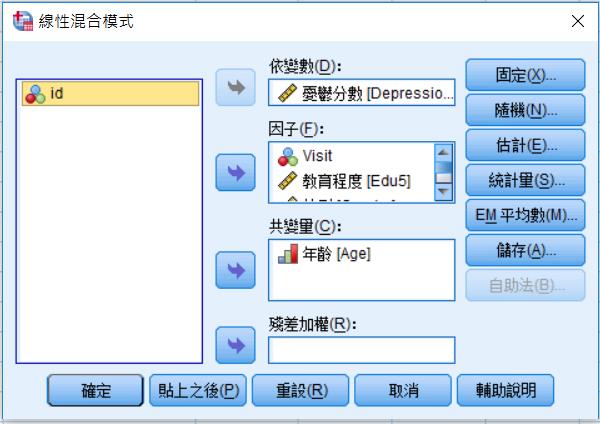
應變項:點選depression。
因子:選Visit、教育程度、性別、回診時間。
共變量:年齡
【固定效果】
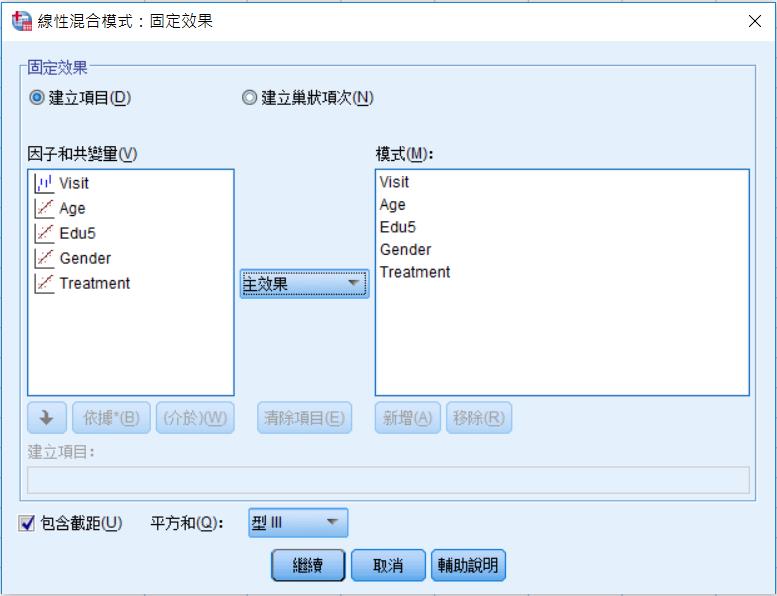
選取主效果,然後把因子跟共變量放進模式裡。
【統計量】
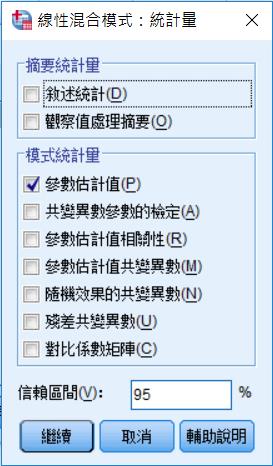
記得勾選參數估計值。
四、分析結果:
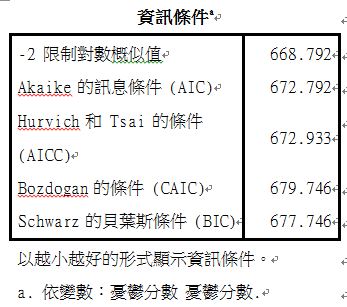
透過AIC及BIC可以得知哪個是最好的共變結構假設,選數值越小越好。所以可以跑不同的共變結構假設後,選取AIC及BIC最小的當最後的模式。本次例子中是複合對稱(Compound symmetry)的模式最適合。
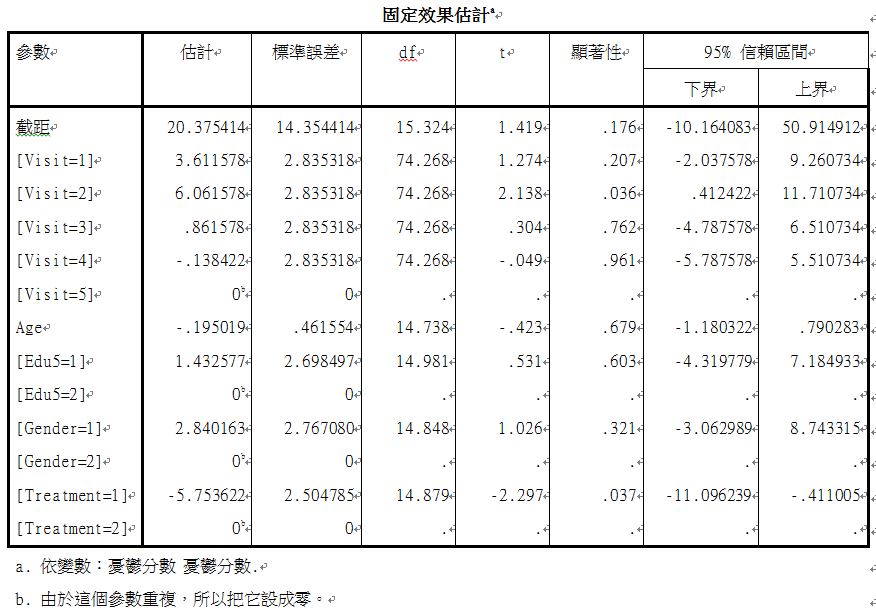
由上表可以看出,控制了性別、教育程度、年齡之後,治療組相較於安慰劑組憂鬱分數少5.7分,且達到顯著上的差異(p=0.037)。性別、教育程度、年齡皆沒有顯著差異(p>0.05)。
本次教學範例檔如下網址所示,僅供同學練習使用:

封面圖-500x383.png)

