
多元迴歸分析用於探討多個預測變數及一個依變數之間的關係。
本篇文章介紹多元線性迴歸分析- R語言的操作(下),細節如下所述。
(四)變數篩選
在多變數迴歸分析中,我們時常會疑惑到底要放入哪些變數,放入太多的變數可能會擔心模型出現共線性或過度擬合導致預測精確度下降的問題,放入太少的變數則似乎無法達到使用多變數分析的目的。這裡的檢測方式採用逐步迴歸分析法和層次迴歸法來做變數篩選。
- 逐步迴歸分析法(stepwise regression)
是利用自動化的過程來選擇變數進入解釋變數集合中或從解釋變數集合中刪除變數,藉此找出最合適的迴歸模型。
MASS包中的stepAIC()函數可以實現模型的逐步迴歸(向前、向後和向前向後),依據的是精確AIC準則。
AIC(Akaike information criterion)為評估模型複雜度與擬合度的指標,可以用來比較模型。AIC值越小的模型表示用較少的參數獲得足夠的擬合度,可優先選擇。
##逐步迴歸篩選變數##
install.packages(“MASS”) #安裝套件:MASS
library(MASS) #載入套件:MASS
stepAIC(lm.reg,direction = “backward”) #向後法逐步迴歸

=>根據執行結果:顯示了逐步迴歸的初始模型與終止模型,終止模型中刪掉「性別(sex) 」和「缺席次數(absent)」這2個變數後,AIC減小,也就是說在模型中只保留「作業分數」、「期中考」、「期末考」和「學期總分」。
- 層次迴歸法
通過逐個增加自變數的方法建立多個模型,以查看每個自變數與依變數的關聯是否有統計學意義;另外對多個模型進行比較,以確定最佳的模型。
##擬合多個模型##
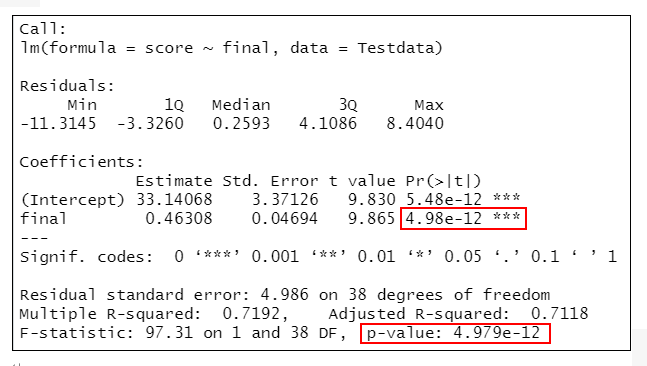
#A模型:學期總分~期末考
lmMode1<-lm(score~final,data=Testdata)
summary(lmMode 1) #輸出模型的結果
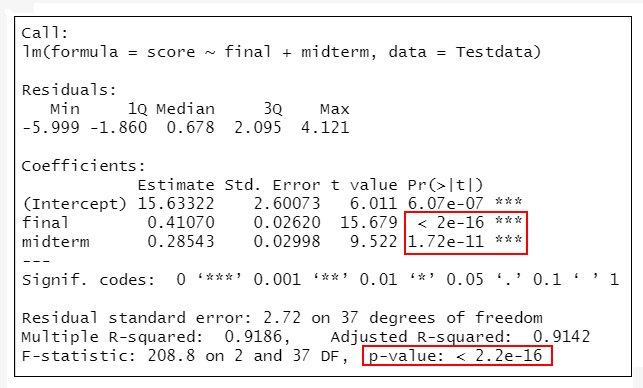
#B模型:學期總分~期末考+期中考
lmMode2<-lm(score~final+midterm,data=Testdata)
summary(lmMode 2) #輸出模型的結果
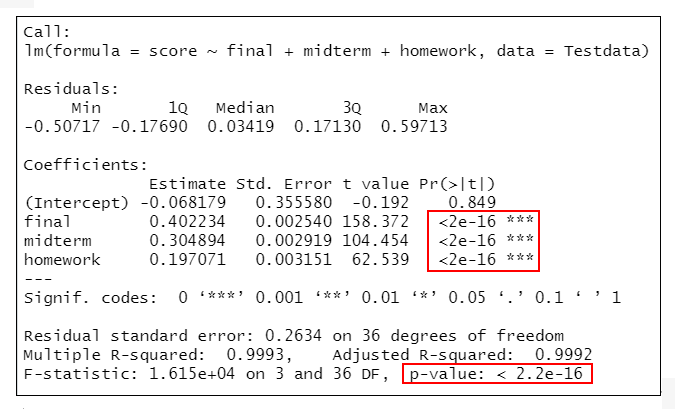
#C模型:學期總分~期末考+期中考+作業分數
lmMode3<-lm(score~final+midterm+homework,data=Testdata)
summary(lmMode 3) #輸出模型的結果
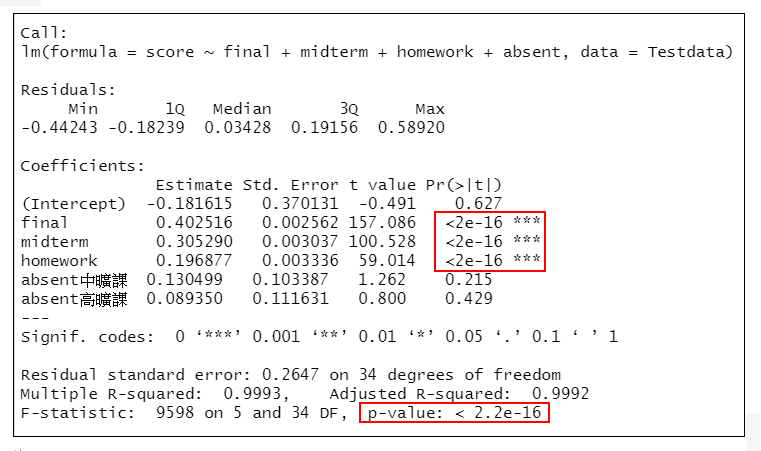
#D模型:學期總分~期末考+期中考+作業分數+缺席次數
lmMode4<-lm(score~final+midterm+homework+absent,data=Testdata)
summary(lmMode 4) #輸出模型的結果
#E模型:學期總分~期末考+期中考+作業分數+缺席次數+性別
lmMode5<-lm(score~final+midterm+homework+absent+sex,data=Testdata)
summary(lmMode 5) #輸出模型的結果
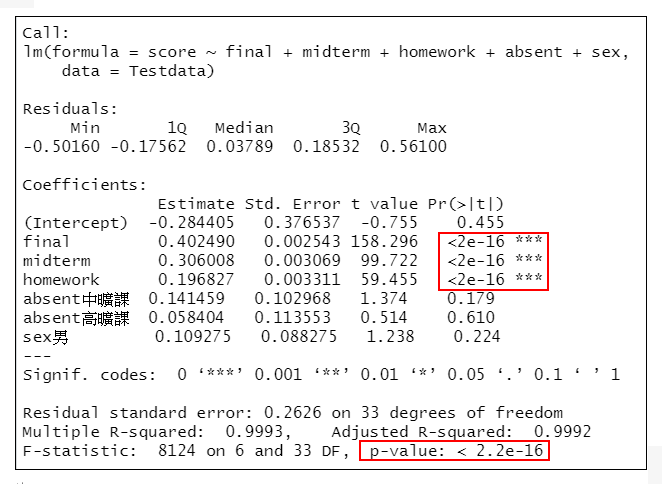
=>根據執行結果:在5個模型(A~E模型)中變數homework、midterm、final均有統計學意義,在E模型中sex、absent與score的關聯無統計學意義。
##對多個模型進行比較##
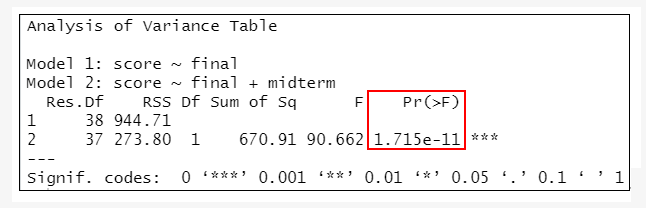
anova(lmMode1, lmMode2)
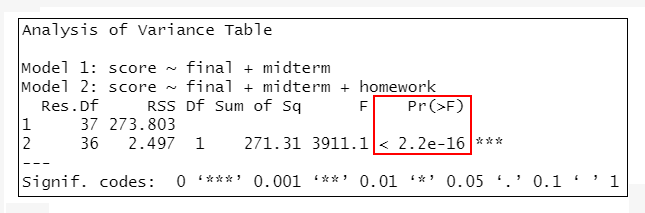
anova(lmMode2, lmMode3)
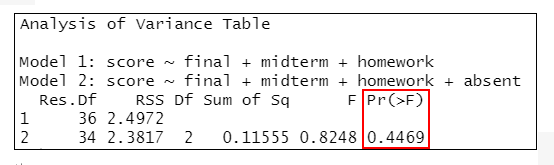
anova(lmMode3, lmMode4)
anova(lmMode4, lmMode5)
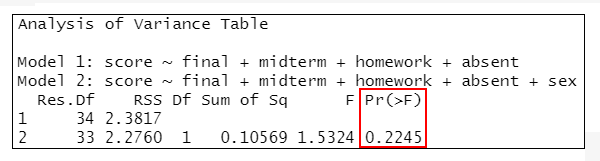
=>根據執行結果:lmMode1與lmMode2相比、lmMode2與lmMode3相比,差異均有統計學意義(P<0.001);但lmMode3與lmMode4相比(P=0.4469)、lmMode4與lmMode5相比(P=0.2245),差異無統計學意義。
從(1)(2)的結果顯示,sex和absent無統計學意義,說明變數sex和absent應從模型中移除。
(五)模型擬合
##建立移除變數(性別、缺課次數)之後的迴歸模型##
lmMode.new<-lm(score~final+midterm+homework, data=Testdata) #移除性別、缺課次數
##查看模型擬合情況##
summary(lmMode.new)
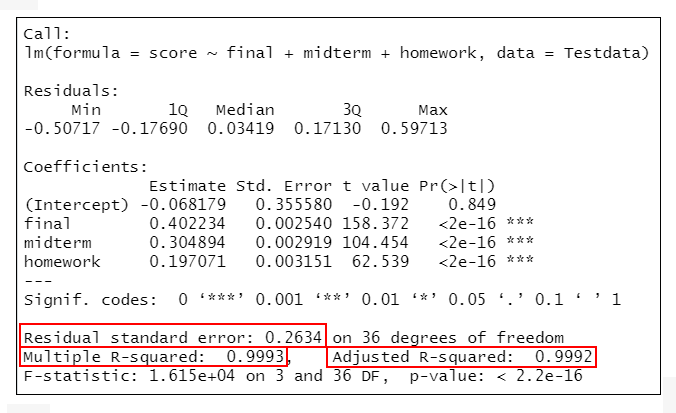
=>根據執行結果:列出了擬合後模型的各項參數。
最終模型的決定係數為0.9993,校正決定係數為0.9992,均方根誤差為0.2634,表明模型整體擬合較好。
即整體模型檢驗結果顯示F=1.615e+04,P<0.001,表示模型有統計學意義。如果P>0.05,則說明模型沒有統計學意義。
Coefficients部分列出了截距和自變數的Estimate (非標準化係數)、Std.Error (標準誤差)、統計量t值及P值。結果顯示模型中的所有自變數均有統計學意義(P<0.001)。
##計算模型中變數係數的95%CI##
confint(lmMode.new)

=>根據執行結果:顯示模型lmMode.new的所有變數係數的95%CI。
迴歸模型的截距為-0.068,表示自變數取值為0時,該變數的係數對依變數沒有影響,而當自變數取值為1時,其係數會改變截距。
變數「期末考」的非標準化係數(即斜率)為0.402 (95%CI:0.397~0.407,P<0.001),
表示「期末考」每增加1分,「總成績」增加0.402分;
變數「期中考」的非標準化係數(即斜率)為0.305 (95%CI:0.299~0.311,P<0.001),
表示「期中考」每增加1分,「總成績」增加0.305分;
變數「作業」的非標準化係數(即斜率)為0.197 (95%CI:0.191~0.203,P<0.001),
表示「作業」每增加1分,「總成績」增加0.197分。
依據上述解析可以寫出本案例的迴歸方程為:
總成績= -0.068 + 0.402×期末考+ 0.305×期中考+ 0.197×作業
根據此方程輸入相關自變數數值即可對總成績進行預測。
四、結論
本研究採用多元線性迴歸模型來分析學期總分是否受到其他因素(性別、缺席次數、作業分析、期中考、期末考)影響。
透過繪製散佈圖,表示自變數(作業分析、期中考、期末考)與依變數(學期總分)之間存在線性關係;透過Durbin-Watson檢定表示資料之間相互獨立;透過庫克距離分析,表示資料不存在需要刪除的異常值;透過共線性診斷,表示自變數之間不存在嚴重共線性問題;通過Shapiro-wilk檢定及繪製殘差Q-Q圖,表示殘差符合常態分配;通過繪製殘差圖,表示殘差符合變異數同質性。本研究資料滿足線性迴歸分析條件。
多重線性迴歸分析執行結果為,在其他變數不變的情況下,變數「期末考」的,「期末考」每增加1分,「總成績」增加0.402分 ( β:0.402、95%CI:0.397~0.407、P<0.001);「期中考」每增加1分,「總成績」增加0.305分 ( β:0.305、95%CI:0.299~0.311、P<0.001);「作業」每增加1分,「總成績」增加0.197分 ( β:0.197、95%CI:0.191~0.203、P<0.001) 。
線性迴歸分析方程為:總成績= -0.068 + 0.402×期末考+ 0.305×期中考+ 0.197×作業;迴歸模型具有統計學意義,F=1.615e+04,P<0.001;此模型可以解釋99.9%的依變數的變異,影響程度較高(adjusted R-squared=0.9992)。
#補充:多元線性迴歸分析(Multiple regression analysis)- R語言操作(上) – 適用條件驗證

封面圖-500x383.png)

