
一、向量(vector)
(一)認識向量
不知道大家聽到向量,會不會回憶起高中時間數學的不好印象,那這邊可以先跟大家掛保證,R語言裡面應用的向量,不會像高中數學時期那麼複雜,且相當直觀好理解喔~
在我們日常處理資料時,可能會一張完整的表(像是excel那樣的工作表),那麼當我們想要分析某列或是某行的時候,就會分別視為一個向量。而向量是一維資料的表現方式,用c()函數定義,參考以下範例:
vec_sample <- c(‘w’,’x’,’y’,’z’)
vec_sample

在範例當中,w~z視為vec_sample向量中的元素(element),各個元素就像是排列好的乘客,它們依照順序乘坐在該向量列車中!
(二)向量順序
提到了順序這個概念,那麼我們就可以透過選定,來提取向量中第n個元素:
vec_sample[1]
vec_sample[c(2,3)]

第一個程式碼vec_sample[1]是提取在vec_sample向量中的第1個元素,也就是“w”。
注意!而若是同時要提取多個元素,並不是vec_sample[2,3] 喔~而是要vec_sample[c(2,3)],在提取裡面還需要放一個向量喔!
(三)向量中的資料型態
在同一向量中,有個必須遵守的規則,那就是所有元素的資料型態必須是相同的,也就是我們上一小節介紹的數值(numeric)、字串(character)和布林代數(logic)。
而若是不同型態的資料放進同一向量,則會直接被轉成一樣的:
vec_sample2 <- c(1,300,’yes’,’no’)
vec_sample2
![]()
在範例當中,我們將數值(1,300)和字串(yes,no)放進同一個向量中。可以看到最後數值資料都被轉為字串的資料型態了,那麼大家不仿可以試試若是把logic和numeric會被轉為哪個呢?
(四)連續向量
若是要產生一個連續性的向量,例如1,2,3,4 ,我們可以不需要一個一個把元素定義進一個向量裡,而是可以利用:或者seq()
來串起第一元素和最後一元素:
1:100
seq(from=1,to=100,by=1) #1 ~ 100 , 數字間隔1
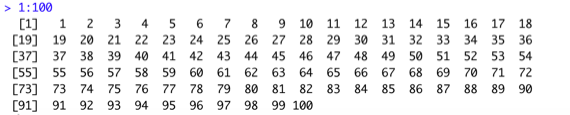
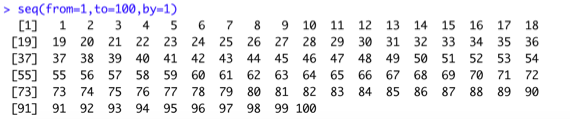
若是想要列出0~50中雙號:
seq(from=0,to=50,by=2)

(五)向量運算
個別向量或者多個向量之間都是可以做數學運算的,當然若是要進行向量之間的運算,則要向量內的元素數目相等!那就直接來看向量間如何運算:
vec_sample3 <- 10:20
vec_sample4 <- seq(from=1,to=33,by=3)
(vec_sample3 + 100) ^ 2 # 所有元素先+100再取平方
vec_sample4 – vec_sample3

二、因子(factor)
因子又稱類別變數,舉例:性別(生理男、生理女)、年級(大一、大二、大三、大四)、地區(北部、中部、南部、東部),當我們遇到以上這類變數時,會轉換成 fator 型態來做分析。
school_gender_sample <- c(‘male’,’female’,’male’,’male’,’male’,’female’)
school_gender_sample <- factor(school_gender_sample)
levels(school_gender_sample)

可以看到以上範例,首先我們先將學校學生性別定義為一向量,然後將此向量轉換成factor型態,最後我們即可以用levels()來找出該項目中,存在了哪些類別。
看到這裡可能會有些許同學會有疑問,怎麼factor和向量很像?其實沒錯,只是factor資料型態相較於vector額外多了類別屬性(levels)。
三、列表(list)
介紹列表(list)之前,先幫各位大家回憶一下,在前面介紹向量(vector)時有個必須要遵守的規定,即是在一向量當中,所有變數的資料型態必須要相同,否則R會自動幫我們轉化成同一個型態。
然而我們有時候想儲存或分析一資料時,資料裡往往存在著許多不同資料類型,那麼我們就將使用列表list()函數來儲存!!舉例某賣場要建立會員資料時,裡面資料可能就包含性別(character)、年齡(numeric)、居住地(character)等等。
首先將顧客資料建立好:
consumer_1 <- list(gender=’male’,
age=18,
region=’Taipei’)
consumer_2 <- list(gender=’female’,
age=23,
region=’Tainan’)

接著我們可以先使用str()函數查看列表內資料型態有哪些:

*小補充:那麼我們將資料儲存進去之後,如果想要隨時查看,當然也要可以提取出來才行,例如我們想看某個顧客的性別或居住地,只要使用R語言裡最特別的程式碼$就可以將顧客內的變數提取出來查看!
consumer_1$gender #查看顧客1的性別
consumer_2$age #查看顧客2的年齡

四、矩陣(matrix)和資料框架(data frame)
(一)矩陣(matrix)
R語言中列出矩陣的方式也相當直觀簡單,通常直接使用matrix() 函式定義,可以跟著以下範例練習:
matrix_sample <- matrix(c(1:8),
nrow = 4,
ncol = 2)
matrix_sample

範例中欲建立一 4×2之矩陣,可以看到變數 nrow= 代表列數,而ncol= 則代表行數,接著建立數字1~8之向量放在此4×2矩陣之中。
而在學習向量時,有提到因向量之元素具有順序的特性,因此可以將某特定位置之元素提取出來查看。那麼在矩陣當中,每個元素也都有自己專屬的位置,例如(1,1)(2,3),而當元素具有固定座位時,我們當然也能將它提取出來檢視囉:
matrix_sample[4,1] #使用的是[]
matrix_sample[3,2]
matrix_sample[2,] #檢視第二列,因此在行的欄位空白
matrix_sample[,1]

矩陣也可以做運算,在單一個矩陣當中做數學運算就和在單一向量中方法相同,大家可以動手試試看喔!而在多個向量中做相乘就有個特別的符號%*% 要記一下囉~相信大家在高中也學過怎麼樣的兩個向量才能做運算吧,不要全部都還給高中數學老師喔~
#另外定義一個2×6矩陣
matrix_sample2 <- matrix(c(21:32),
nrow = 2,
ncol = 6,)
matrix_sample2
matrix_sample%*%matrix_sample2 #兩矩陣相乘

(二)資料框架(data frame)
1.認識資料框
R語言中data frame可以直接理解成我們平常在excel中作業的sheet表,以下範例使用R語言內建鐵達尼號存活資料來呈現給大家看:
install.packages(“titanic”) #安裝並啟動鐵達尼套件
library(titanic)
View(titanic_train) #使用View()函數查看完整鐵達尼訓練資料
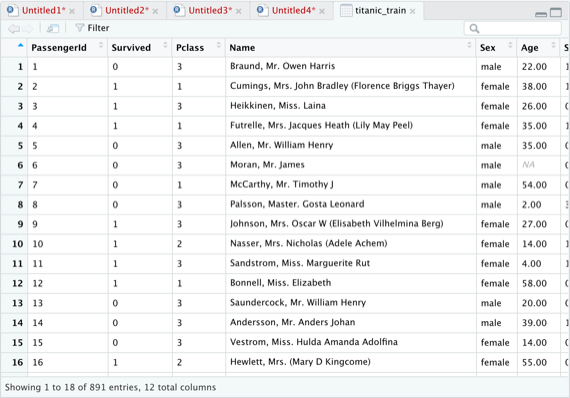
在使用View()此函數後,會跑出類似sheet表單,也就是R語言的data frame !
2.製作資料框
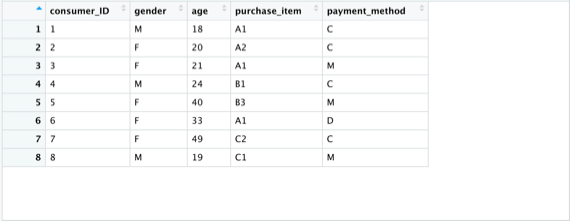
如同先前的向量以及矩陣,資料框在R語言裡當然也能運用特定函數 data.frame() ,那麼就一起來創造獨特的資料框吧:

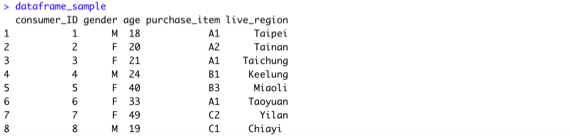
View(dataframe_sample)
3.閱讀資料框
不管是R語言內建、我們自己建立的或者從外部匯入的資料框,可能都具有相當龐大的資訊量。那麼要未來如果想使用它或者分析它,就必須先完全理解它所有變數的資料型態、資料量等等資訊。除了上述所提到的View() 函數,我們還可以利用以下函數檢視不同資訊:
(1) head() 函數
首先,能取代View() 的一函數,由於每次使用View函數都會大量運用到電腦資源,因此我們找到能代替其並且閱覽功能相差不遠之函數,而head() 函數特色就是顯示前6項資料,可看作縮小版的View函數:
head(dataframe_sample)

(2)str()函數
論檢視變數資料型態,幾乎沒有比str()函數更好用的了,它不僅僅可以看出每個定義出來資料的資料結構(向量、矩陣、列表、資料框),更可以顯示每個資料集合的所有變數的資料型態(數值、字串、布林代數):
str(dataframe_sample)

可以看到以上範例,會直接顯示此資料集合:data frame結構,8筆資料數和5個變數。另外在每個變數裡會顯示資料型態,例如在gender變數,是屬於factor類型且分為兩種levels 。
(3)summary()函數
最後一個summary()函數,是一個能夠檢視每個變數內的描述性統計(平均數、中位數、個數等等)功能:
summary(dataframe_sample)

4.調整資料框變數
常見資料框都會有缺少變數或者擁有多餘用不到之變數問題,而為了使用以及分析上方便,我們常會透過新增以及刪除變數來調整原有資料框:
新增變數相當簡單,只要另外指派新的向量給原本資料框即可:
dataframe_sample$live_region <- c(“Taipei”,
“Tainan”,
“Taichung”,
“Keelung”,
“Miaoli”,
“Taoyuan”,
“Yilan”,
“Chiayi”)

而刪除變數,只要將欲刪除之變數指派給NULL即可:
dataframe_sample$payment_method <- NULL
*小結:恭喜各位到這裡也已經學會R語言最基本也是最重要的資料結構了,在理解完這章節的資料結構和上章節的資料類型,接下來我們就可以開始學習如何整理資料結構和資料清洗了!
封面圖-500x383.jpg)
封面圖-500x383.png)

封面圖-500x383.png)