
簡單線性迴歸分析用於探討單一自變數及依變數之間的關係。
本篇文章介紹簡單線性迴歸分析- R語言的操作,細節如下所述。
# 補充:簡單線性迴歸分析相關內容(SPSS)
https://www.yongxi-stat.com/simple-regression-analysis/
一、分析目的
迴歸 (regression) 方法是一個分析變數和變數之間關係的工具,主要在探討自變數(x)與依變數(y)之間的線性關係,透過迴歸模型的建立,可以推論和預測研究者感興趣的變數(y)。
二、適用條件
使用簡單線性迴歸分析需要滿足以下6個條件:
條件1:自變數和依變數為連續變數。
條件2:自變數和依變數之間具有線性關係。
條件3:觀察變數沒有異常值。
條件4:觀察變數相互獨立。(獨立性)
條件5:依變數的觀測值来自常態分配且變異數相同。(常態性)
條件6:殘差為變異數同質性。(變異數同質性)
三、R語言操作範例
(一) 範例介紹
十位學生統計學期中考和期末考的成績如下:

想瞭解期中考與期末考的分數是否有關,並希望藉由期中考的分數來預測期末考的成績。
自變數(X):期中考成績
依變數(Y):期末考成績
(二) 資料匯入
ExamData<-read.csv(“Test.csv”,header=T) #將資料匯入到指定的變數,也就是ExamData
View(ExamData) #瀏覽資料內容
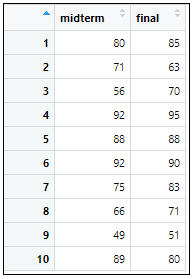
=>根據執行結果:在資料集中共有2個變數和10個觀察資料,2個變數分別為:期中考(midterm)、期末考(final)。
(三) 適用條件判定
- 條件1判斷(變數判斷)
本範例的期中、期末考分數為連續變數,滿足適用條件1「自變數和依變數為連續變數」。
- 條件2判斷(線性關係判斷)
這裡的檢測方式採用散佈圖,用來判別資料之間,是否有相關聯性
# 補充:散佈圖(Scatter Plot)
是表示兩個變數之間關係的圖,又稱相關圖。
依下列(A)~(F)的判斷方式,檢視是否為不相關。
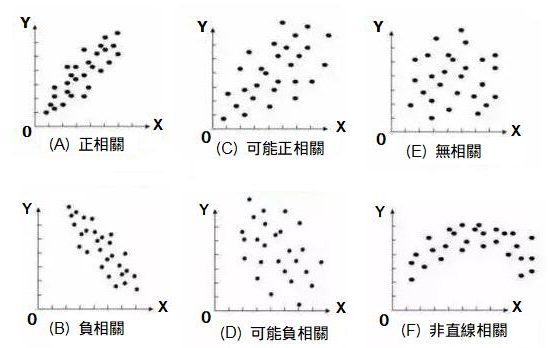
圖1. 散佈圖的判斷方式
##線性關係判斷 ##
install.packages(“ggplot2”) #安裝套件:ggplot2
library(ggplot2) #載入套件:ggplot2
ggplot(data=ExamData,aes(x=midterm,y=final))+geom_point()+stat_smooth(method=”lm”,se=TRUE) #繪製散佈圖
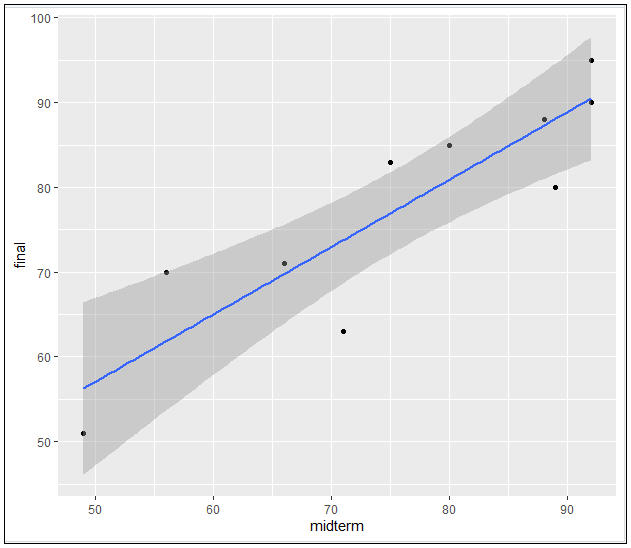
圖2. 期中考(midterm)與期末考(final)的散佈圖
=>根據執行結果:期中考與期末考成績呈線性相關(正相關),滿足適用條件2「自變數和依變數之間具有線性關係」。
- 條件3判斷(異常值檢測)
通過圖2的散佈圖可知,資料不存在異常值。但仍需要統計分析結果的判斷。
庫克距離(Cook’s Distance)用來判斷強影響點是否為依變數的異常值點。一般認為當D<0.5時不是異常值點,當D>0.5時認為是異常值點。
##計算cook距離 ##
lm.reg<-lm(final~midterm,data=ExamData) #迴歸分析
cook<-cooks.distance(lm.reg) #計算cook距離
cook[cooks.distance(lm.reg)>0.5] #顯示cook距離>0.5的個案編號和cook值
max(cook) #顯示最大cook距離

=>根據執行結果:顯示最大庫克距離D為0.454<0.5,表示資料不存在異常值,滿足適用條件3「觀察變數沒有異常值」。
- 條件4判斷(獨立性判斷)
Durbin-Watson檢定:
通常用來檢測迴歸分析中的殘差項是否存在自我相關,Durbin-Watson檢定值分佈在0~4之間,越接近2,觀測值相互獨立的可能性越大。需要注意的是,判斷觀測值是否獨立,主要取決於研究設計和資料收集階段的品質控制,Durbin-Watson檢驗最好用於輔助判斷。
##獨立性判斷##
install.packages(“car”) #安裝套件:car
library(car) #載入套件:car
durbinWatsonTest(lm(final~midterm, data=ExamData)) #Durbin-Watson檢定

=>根據執行結果:顯示DW Statistic為2.057,P=0.95,說明觀測值相互獨立,滿足適用條件4「觀察變數相互獨立」。
- 條件5判斷(殘差的常態性檢定)
這裡的檢測方式採用分位元圖(Q-Q圖)和Shapiro-Wilk檢定來做是否為常態分配。
#補充:分位圖(Q-Q圖)
是一種視覺化比較兩項數據的分佈是否相同的方法。
另外,Q-Q Plot不是只有判斷「是否為直線」或者「是否為常態分配」,即使畫出來的不是直線,還是能看出資料分配的特性。
從圖3 中可以看到Q-Q Plot在左偏與右偏分配會呈現的樣子:
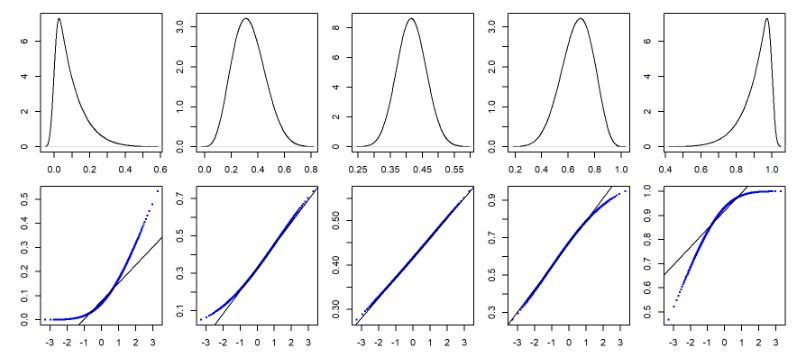
圖3 不同數值分配下的不同 Q-Q Plot(Source: Manny Gimond)
(1) 繪製Q-Q圖:
qqnorm(lm.reg$residuals) #繪製qq圖
qqline(lm.reg$residuals) #增加趨勢線
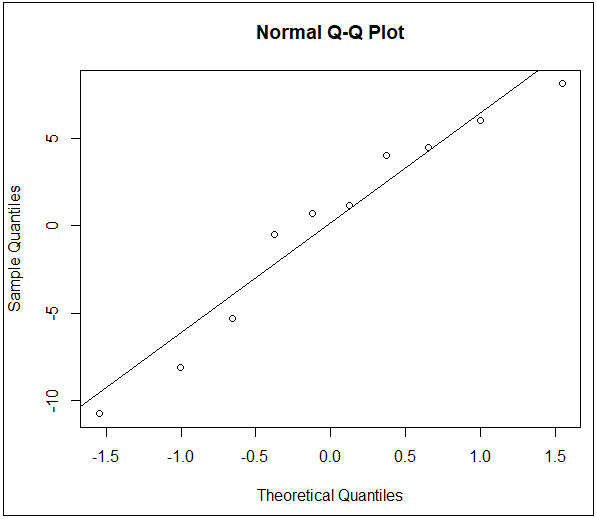
圖4期中考(midterm)與期末考(final)的Q-Q圖
=>根據執行結果:資料點基本上都圍繞對角線分佈,表示殘差呈常態性分配。
#補充:使用S-W檢定的原因
要進行常態性檢定有兩種方法K-S檢定或S-W檢定,因樣本數的關係而選擇使用S-W檢定。
Kolmogorov-Smirnov(K-S)檢定:樣本數50個以上。
Shapiro-Wilk(S-W)檢定:樣本數50個以下。
(2) 常態性檢定:
shapiro.test(lm.reg$residuals)

=>根據執行結果:顯示 P=0.5615>0.1,表示殘差呈常態性分配。
結合(1)(2)的結果,表示資料滿足適用條件5「依變數的觀測值来自常態分配且變異數相同」。
- 條件6判斷(殘差的變異數同質性檢定)
##殘差圖##
par(mfrow=c(1,3)) #繪製一行3個圖
plot(lm.reg$residuals)
plot(ExamData$final,lm.reg$residuals)
plot(ExamData$midterm,lm.reg$residuals)
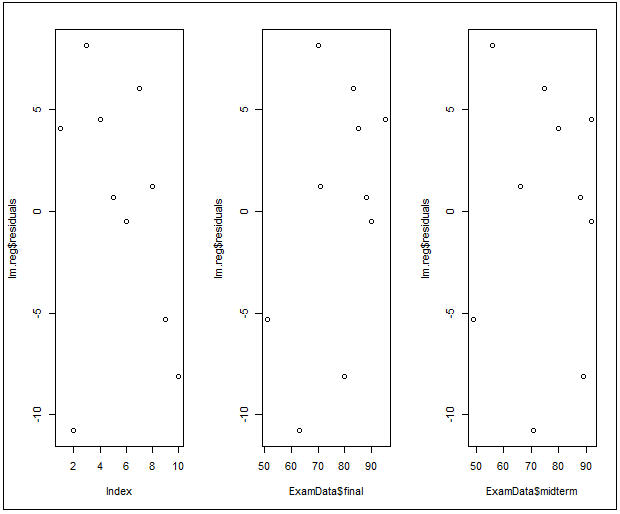
=>根據執行結果:預測值和各變數值的殘差分佈較為均勻,並未出現特殊的分佈形式(如漏斗或者扇形),表示殘差符合變異數同質性,滿足適用條件6「殘差為變異數同質性」。
(四) 模型擬合
##查看模型擬合情況##
summary(lm.reg)
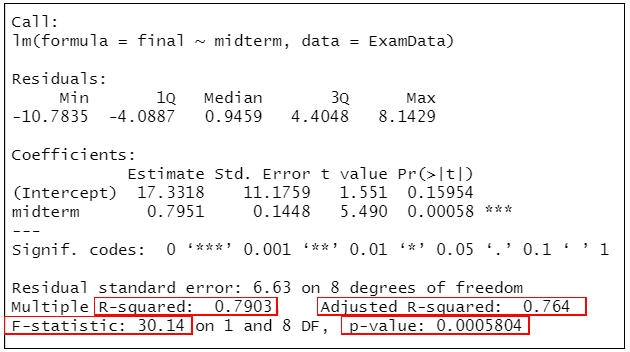
=>根據執行結果:列出了擬合後模型的各項參數。
(1) 模型擬合程度
決定係數R2=0.7903,表示自變數(期中成績)可以解釋79.03%的依變數的變異(期末成績),但是R2會受自變數個數的影響,誇大自變數對依變數變異的解釋程度,自變數越多,R2越大。Adjusted R2調整了自變數個數對結果的影響,一般小於R2。Adjusted R2=0.764,表示自變數(期中成績)可以解釋76.4%的依變數的變異(期末成績)。
整體模型檢驗結果顯示F=30.14,P<0.001,表示模型有意義。如果P>0.05,則說明迴歸沒有統計學意義。
(2) 迴歸係數解釋
Coefficients部分列出了截距和自變數的 “Estimate (非標準化係數) “、”Std.Error (標準誤) “、統計量t值及P值。可知,迴歸模型的截距為17.3318,表示自變數取值為0時,依變數的取值,並無實際專業意義。變數 “midterm” 的非標準化係數(即斜率)為0.7951,表示期中成績每增加1分,期末成績就會增加0.7951分。依據上述解析可以寫出本案例的迴歸方程為:
final =17.3318+0.7951×midterm
根據此方程可以計算合理範圍內期中成績對應的期末成績了。
四、結論
本研究採用簡單線性迴歸模型藉由期中考的分數來預測期末考的成績。透過繪製散佈圖,表示兩者之間存在線性關係;透過Durbin-Watson檢定表示資料之間相互獨立;透過繪製散佈圖和庫克距離分析,表示資料不存在需要刪除的異常值;通過Shapiro-wilk檢定及繪製殘差Q-Q圖,表示殘差符合常態分配;通過繪製殘差圖,表示殘差符合變異數同質性。本研究資料滿足線性迴歸分析條件。
線性迴歸分析方程為:final =17.3318+0.7951×midterm,迴歸模型具有統計學意義,F=30.14,P<0.001;自變數(期中成績)可以解釋79.03%的依變數的變異(期末成績),影響程度較高(adjusted R2=0.764),即期中成績每增加1分,期末成績增加0.7951分。



