
卡方分配(chi-square distribution)是統計學常用的一種機率分佈,可應用於類別資料分析。
在實際應用中,最常見的有三種方法:獨立性檢定、同質性檢定、適配度檢定。
本篇文章主要介紹卡方同質性檢定– R語言的操作,細節如下所述。
# 補充1:卡方同質性檢定相關內容(SPSS)
https://www.yongxi-stat.com/chi-test-of-homogeneity/
# 補充2:「卡方獨立性檢定」跟「卡方同質性檢定」的方法是一樣的,然而兩個切入的角度完全不一樣。
兩者的差別是「卡方獨立性檢定」主要探討的是「資料關聯性」,而「卡方同質性檢定」探討的則是「各類別比例是否相同」
一、分析目的
檢定兩個或兩個以上的母體某一特性的分配是否相同或相近
二、卡方同質性檢定的計算方式
(1) 假設檢定
虛無假設(Null hypothesis)→ H0:B1, B2,…,Bc的母體分配相同。
對立假設(alternative hypothesis)→ H1:B1, B2,…,Bc的母體分配不全相同。
(2) 顯著水準 α
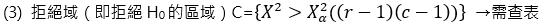
(4) 計算檢定統計量:

(5) 結論:當X2 ∈ C時,則拒絕H0,否則,接受H0。
三、R語言操作範例
(一) 範例介紹
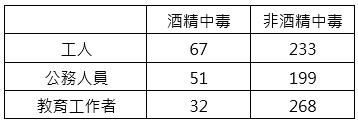
針對各行業工作者酒精中毒的研究,調查對象有工人、公務人員及教育工作者,經實際觀察850位受訪者資料得如下表,試以顯著水準α = 0.05檢定此三種行業工作者酒精中毒的比例有無差異。
(1) 設三種行業工作者患有酒精中毒的比例分別為p1、p2及p3,其假設檢定為:
虛無假設→ H0:p1=p2=p3 即三種行業工作者患有酒精中毒的比例是相同的;
對立假設→ H1:pi不全相同,i=1,2,3 即三種行業工作者患有酒精中毒的比例是不相同的。
(2) 顯著水準 α = 0.05
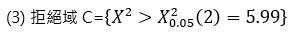
(二) 資料匯入
Alcoholisms<-read.csv(“Alcoholism-3.csv”,header=T)
# read.csv ():將資料匯入到指定的變數,也就是Alcoholism
View(Alcoholisms)
# View():瀏覽資料內容
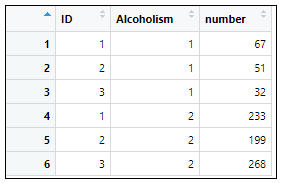
=>根據執行結果:在資料集中共有3個變數和6個觀察資料,3個變數分別為:
身分(ID):1工人、2公務人員、3教育工作者;酒精中毒(Alcoholism):1酒精中毒、2非酒精中毒;比例(number)
(三) 統計描述
- 資料整理
data<-data.matrix(Alcoholisms$number) #取number資料轉矩陣格式
rname<-c(“Worker”,”civilservant”,”educators”) #行名稱
cname<-c(“Alcoholism”,”no Alcoholism”) #列名稱
compare<-matrix(data,nrow=3,ncol=2,dimnames=list(rname,cname)) #資料整理並編輯為矩陣格式
compare #查看數據
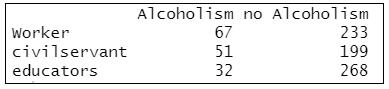
=>根據執行結果:列出了卡方檢驗所需要的資料格式,並存儲在「compare」資料框中
- 統計描述
##計算各行業工作者酒精中毒比例##
S1<-prop.table(compare, margin = 1) #計算行百分比
S1 #顯示行百分比
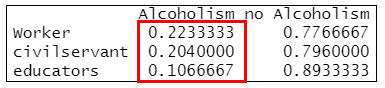
=>根據執行結果:酒精中毒比例分別為:工人22%、公務人員20%、教育工作者10%
(四) 統計推斷
##卡方檢驗##
S2<-chisq.test(compare,correct = FALSE) #不進行連續性校正
S2$expected #查看期望次數

=>根據執行結果:可知表格內的期望次數均>5。
# 補充:在卡方檢定中,一般要求期望次數不得小於1,並且不得有20%以上細格的期望次數小於5。
不然則建議合併相鄰的行或列,或採用Yate’ s correct test,或採用Fisher’ s Exact Test。
S2 #查看卡方檢驗結果

=>根據執行結果:顯示卡方統計量、自由度和P值,可知三種各行業工作者酒精中毒的比例是有顯著的差異(X2=15.896,P<0.05)。
##計算Cramer V係數##
由於同質性假設只能檢定兩個變數是否相關,無法知道關聯性的強度與方向,因此當檢定結果為顯著相關時,便會依據不同的資料型態 (例如:不同大小的列聯表)選擇不同的係數來計算變數之間關聯性的強度與方向:
- ϕ係數 (phi coefficient):僅適用於2 x 2的列聯表
- 列聯係數 (coefficient of contingency):適用於大於2 x 2方陣的列聯表,如3 x 3、4 x 4、5 x 5
- Cramer’ s V係數:可用於非方陣列聯表,如2 x 3、3 x 2、2 x 4、3 x 4 …
install.packages(“vcd”) #安裝套件:vcd
library(vcd) #載入套件:vcd
assocstats(compare) #計算Cramer V係數
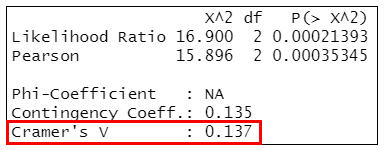
=>根據執行結果:表示各行業工作者與酒精中毒的機率為弱相關(Cramer’s V(Cramer’s係數)=0.137)。
#事後檢定(兩兩比較)
到目前為止,卡方檢定檢出組間差異後,得到的結果只能顯示行變量與列變量間是否相互獨立,但各變量的不同組別間具體存在何種差異呢?這需要後續通過兩兩比較來得到更爲精確的結論。因此可以通過X2分割法進行兩兩比較,即將三組比例的比較拆分成多個兩組比例的比較;同時校正顯著水準以避免第一類錯誤率過度膨脹,校正後的α’=α/m,其中m=k(k-1)/2,k為分組數。本案例為3個分組,拆分成3個兩組比例的比較;取α=0.05,則α’=0.05/3=0.017。
##指定數據子集##
mydata1<-subset(Alcoholisms, ID!=3) #資料子集(工人和公務人員)
mydata2<-subset(Alcoholisms, ID!=2) #資料子集(工人和教育工作者)
mydata3<-subset(Alcoholisms, ID!=1) #資料子集(公務人員和教育工作者)
##兩兩比較##
install.packages(“jmv”) #安裝套件:jmv
library(jmv) #載入套件:jmv
#計算工人和公務人員的比較
contTables(formula = number ~ ID:Alcoholism, data = mydata1, contCoef=TRUE, phiCra=TRUE)
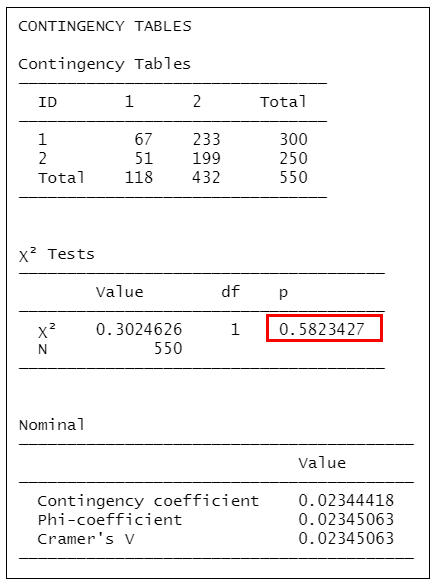
=>根據執行結果:顯示P值為0.5823427>0.017,可知工人和公務人員酒精中毒的比例是無顯著的差異。
#計算工人和教育工作者的比較
contTables(formula = Frequency ~ Therapy:Alcoholism, data = mydata2, contCoef=TRUE, phiCra=TRUE)
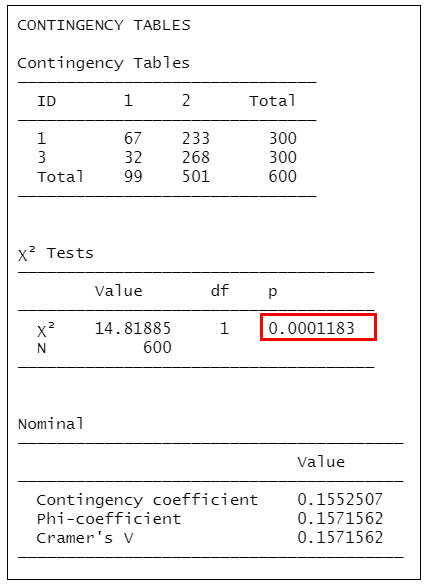
=>根據執行結果:顯示P值為0.0001183<0.017,可知工人和教育工作者酒精中毒的比例是有顯著的差異。
#計算公務人員和教育工作者的比較
contTables(formula = Frequency ~ Therapy:Alcoholism, data = mydata2, contCoef=TRUE, phiCra=TRUE)
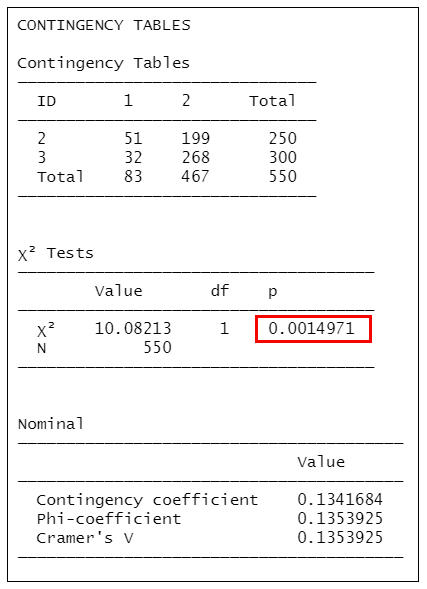
=>根據執行結果:顯示P值為0.0014971<0.017,可知公務人員和教育工作者酒精中毒的比例是有顯著的差異。
四、結論
本研究採用卡方同質性檢定對三種行業工作者患有酒精中毒的比例進行比較,結果顯示工人的酒精中毒比例為22%、公務人員的酒精中毒比例為20%、教育工作者的酒精中毒比例為10%,三種行業工作者患有酒精中毒的比例是有顯著的差異(X2=15.896,P<0.001),表明三種行業工作者患有酒精中毒的比例不全相同,也就是拒絕H0接受H1。
另外採用X2分割法,按照α’=0.017的顯著水準進行兩兩比較,發現工人和公務人員患有酒精中毒的比例是無顯著的差異(P=0.5823427),工人和教育工作者患有酒精中毒的比例是有顯著的差異(P=0.0001183),公務人員和教育工作者患有酒精中毒的比例是有顯著的差異(P=0.0014971)。
封面圖-500x383.png)


