
本篇文章主要說明如何使用STATA進行資料合併的動作(merge),一般而言,資料合併包含縱貫型資料,例如針對同一樣本的持續長時間追蹤調查(panel survey);或是橫斷型資料,例如各年度的橫斷面調查(cross-sectional survey)資料。
若想將多筆資料合併成同一筆資料來分析,這時就需要資料合併的語法了。下述的操作說明將針對橫斷型資料合併 (垂直合併)與縱貫型資料合併 (水平合併)進行說明,細節可參考如下。
一、垂直合併
所謂垂直合併,即是將兩份資料依共同變數,垂直地接合在一起。研究者經常使用 append 指令來執行垂直合併,但是使用 append 指令的先決條件是兩筆欲合併的資料有可以對應且具有相同意義的變數。然而,許多資料庫如臺灣傳播調查資料庫、台灣社會變遷基本調查資料庫的變數名稱會隨時間產生變化,比方說某年某題項的變數是v21,相隔五年增減題項後該題項又對應到v23,或是變數名稱大小寫不同,導致運用 append 合併資料會產生許多麻煩。因此,我們建議就欲合併的資料先分別取用所需變數,並重新命名,如此一來能避免上述變數混淆的情況發生。
執行垂直合併的步驟為:
(一)、開啟第一筆資料,生成所需變項,並儲存檔案
打開第一筆資料後將性別變項v1生成為sex_95(95指1995年的資料),如下圖:
儲存前需要 keep 欲保留下來的變項,並將資料排序(常見做法為使用樣本 id 排序),最後儲存(save “檔案位置/檔案名稱”, replace; ),以下為語法。
keep id_x sex_95 yr_95 age_95 eduyr_95 ;
sort id_x;
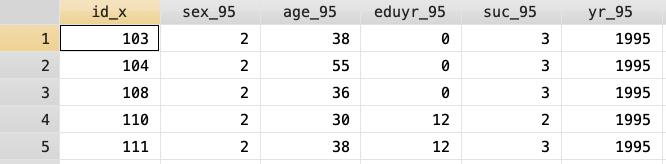
(二)、開啟第二筆以上資料,生成所需變項,並儲存檔案
步驟如同第一步。不過可以注意的是,有時不同年度資料仍會使用同樣的 id 號碼來標示不同樣本,此時可以生成新的 id 變項,將 id 號碼乘以多倍,以免覆蓋既有變項。
gen id_x= id*100000000 ;
第三筆欲合併資料可以乘以更多倍,確保 id 號碼不會重複:
gen id_x= id*10000000000000;
(三)、合併資料
開啟第一份資料後,以新生成的 id_x 為合併參照,將第一筆資料和第二筆資料合併,語法為「 merge id_x , using “檔案位置/第二筆資料的檔案名稱”; drop_merge; 」。接著以 id_x 排序「sort id_x; 」,最後儲存為生成的新資料。要合併三筆資料以上的話必須重複以上語法,語法如下:
use “檔案位置/tscs951_cut”, clear;
merge id_x , using “檔案位置/tscs001_cut”;
drop _merge;
sort id_x;
save “檔案位置/tscs_95_00”, replace;
**合併第三筆資料**;
merge id_x , using “檔案位置/tscs051_cut”;
drop _merge;
sort id_x;
save “檔案位置/tscs_95_00_05”, replace;
**合併第四筆資料**;
merge id_x , using “檔案位置/tscs101_cut”;
drop _merge;
sort id_x;
save “檔案位置/tscs_95_00_05_10”, replace;
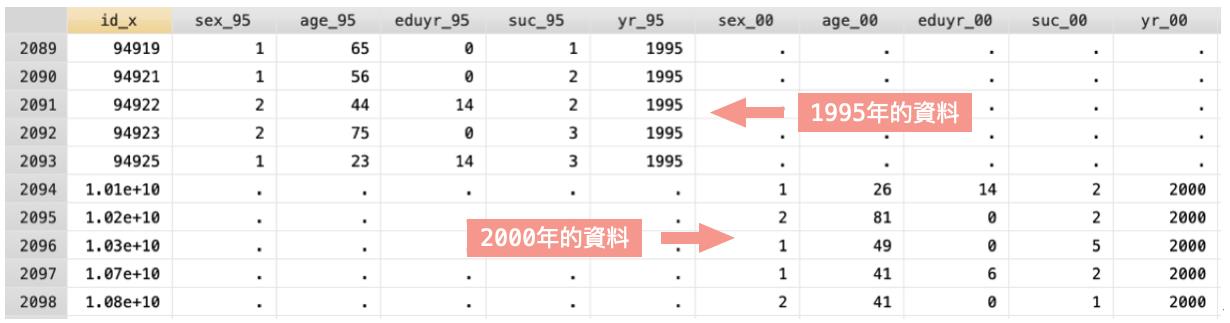
合併後的資料會如圖二:
可以看出每一個變項的column依照年度區隔開來了,於是我們就需要合併變數,否則無法垂直合併各個年度的資料。
(四)、合併變數
我們先前分別生成的變項也需要合併,生成新的整合變數,語法為:
gen year=yr_95 if yr_95<. ;
replace year=yr_00 if yr_00<. ;
replace year=yr_05 if yr_05<. ;
replace year=yr_10 if yr_10<. ;
**性別sex**;
gen sex=sex_95 if sex_95<. ;
replace sex=sex_00 if sex_00<. ;
replace sex=sex_05 if sex_05<. ;
replace sex=sex_10 if sex_10<. ;
每一個欲整合的變項都需要生成新的整合變數,其中 replace 是指覆蓋、代替原檔案的意思,「if 變數<. 」 代表只要不是遺漏值者都加入新的整合變數當中。雖然這些步驟看似麻煩,但可以善用複製貼上或取代功能完成語法。比方說寫好的「性別」整合變項只需被取代為「教育程度」,就可以生成新的「教育程度」整合變項。
成功合併變數的資料如圖三,可以看到年度變項中1995年和2000年的資料在同一column:
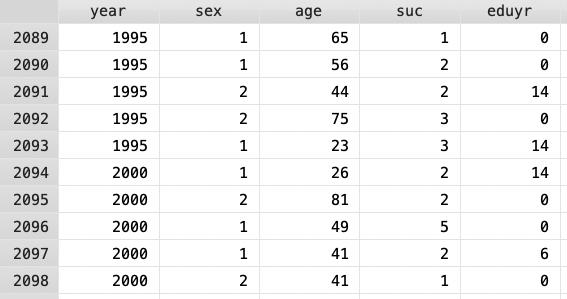
二、水平合併(如果不同年度同一樣本的 id 變數內容相同 [通常追蹤資料會有固定 id] )
為什麼我們需要水平合併?有一個經典的資料處理需求是:追蹤調查(panel survey)。由於追蹤調查是針對某一調查對象長期連續不斷地跟蹤調查,若我們想分析這些樣本中的特性、甚至是隨時間而造成的變化時,首先就需要運用水平合併來處理手上有多筆經由追蹤調查而得的資料。
水平合併是將多筆資料依照某特定變數(經常是利用變數 id),水平串接其餘欄位資料。如下兩張圖,兩者為不同年度的追蹤調查資料,由於 id 指涉同一人,這時就可以水平合併來檢視不同時間帶來的變化。
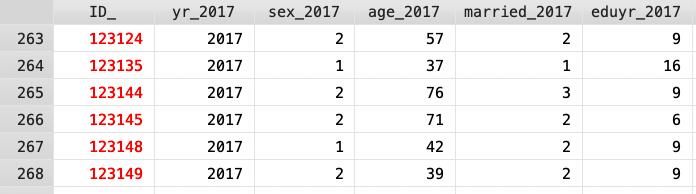
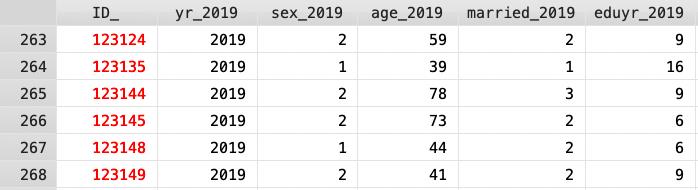
執行水平合併的步驟為:
(一)、開啟第一筆資料,生成新的 id 變數,並儲存檔案
gen id_x= ID;
(二)、開啟第二筆以上資料,生成新的 id 變數,並儲存檔案
gen id_x= id;
(三)、合併資料
開啟第一份資料後,以新生成的 id_x 為合併參照,將第一筆資料和第二筆資料合併,語法為「 merge id_x , using “檔案位置/第二筆資料的檔案名稱”; drop_merge; 」。接著以 id_x 排序「sort id_x; 」,最後儲存為生成的新資料。要合併三筆資料以上的話必須重複以上語法。有沒有發現和垂直合併其實是同樣的邏輯?只要能找到對應的 id_x,就能進行水平合併。

三、水平合併(如果不同年度同一樣本的 id 變數內容不同)
有些資料庫命名樣本 id 時,會在 id 裡面加入不同的英文字母來表示不同主題或不同年度的調查資料,比方說 2017 的資料中某一樣本 id 命名為 T000005(如下圖 ID 為 T 開頭的資料),2019 年追蹤資料對同一樣本的 id 命名為 P000005(如下圖 ID 為 P 開頭的資料),以此來表示不同年度調查的樣本。如果不確定資料庫是不是以此方式命名 id 的,可以閱覽人口學變項,看看 id 數字吻合的樣本是否性別、出生年、教育程度等變項也一致。
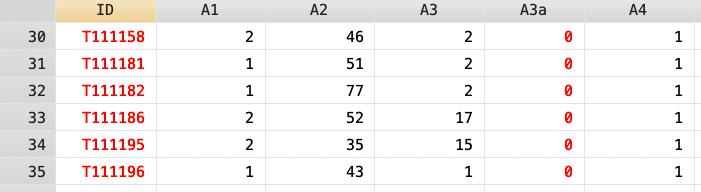
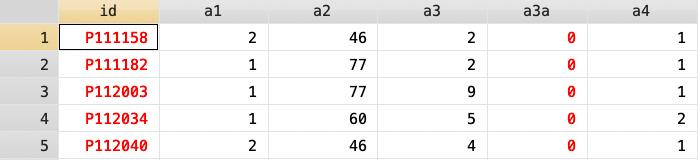
當遇到 id 中有英文字首的情況時,可運用 substring 來編輯 id 名稱,這種執行水平合併的步驟為:
(一)、開啟第一筆資料,生成新的 id 變數,並儲存檔案
gen cluster=substr(ID,2,6);
substr(ID,2,6) 中 ID 指的是原始資料中 id 欄位的變數名稱,第一個數字指的是從第幾位開始起算,第二個數字是納入後面幾位數字,也可以用「 . 」來納入到最末位。簡言之,此語法是將「P000005」從第二位納入到第六位,由此可萃取出「000005」。只要學會這個語法,後續步驟也和上述大同小異。
(二)、開啟第二筆以上資料,生成新的 id 變數,並儲存檔案
gen cluster=substr(id,2,6);
(三)、合併資料
開啟第一份資料後,以新生成的 cluster 為合併參照,將第一筆資料和第二筆資料合併,語法如下:
use “檔案位置/2017_cut”, clear;
merge cluster , using “檔案位置/2019_cut”;
drop _merge;
sort cluster;
save “檔案位置/2017_2019”, replace;
首先「 merge cluster , using “檔案位置/第二筆資料的檔案名稱”; drop_merge; 」。接著以 cluster 排序「sort cluster; 」,最後儲存為生成的新資料。要合併三筆資料以上的話必須重複語法。

成功的水平合併,是指同一個 id 在兩筆資料是同一個人,所以 2000 筆資料去併另一年度的 2000 筆資料,合併後要等於2000筆,這才是正確的水平合併結果。

封面圖-500x383.png)

