
之前在【認識R語言資料結構】中介紹了R語言裡常見的資料結構,並且教導大家如何建立以及閱讀每一種資料結構,而在本篇文章的重點,我們將會介紹如何進行資料分割與合併。
資料分割與合併是進行資料分析之前相當重要的一個環節,尤其像是在做建立迴歸模型、分類模型等會用到的測試資料和訓練資料,就必須利用到分割原始資料和重新分配以及合併資料的的步驟,有了這些步驟才能夠順利的製作出所需要的訓練資料和測試資料。
(一)資料分割
主要使用subset()函式,可以依據你想要的特定變數數值,來進行選擇且切割出來,用我們創建的資料框來做示範(希望將年齡>30歲和年齡<30的消費者資料個別切割出來)
#在subset()函式的第一格內要放的是原始資料集合(欲分割的資料集合)
consumer_old <- subset(consumer, age>30 )
View(consumer_old) #即將原始資料框年齡>30的消費者資料切割出來
consumer_young <- subset(consumer, age<30 )
View(consumer_young) #即將原始資料框年齡<30的消費者資料切割出來

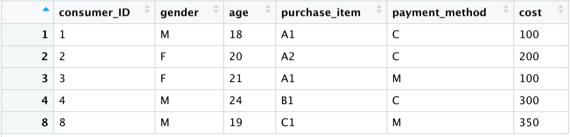
而若我們只想要將年齡>30歲消費者的消費金額分割出來,即在subset函式裡加上一個selcet=即可:
consumer_old <- subset(consumer, age>30, select = cost)
#select= cost 代表只想將cost(消費金額)資料分割出來
View(consumer_old)

consumer_old <- subset(consumer, age>30, select = -cost)
#select= -cost 同理,代表只想將除了cost(消費金額)資料分割出來
View(consumer_old)

(二)資料合併
當我們在進行兩筆以上的資料合併時,主要會使用rbind()函式和cbind()函式,都可以將兩筆資料進行合併,但兩種函式在功能以及限制上都有些微差異,以下進行示範:
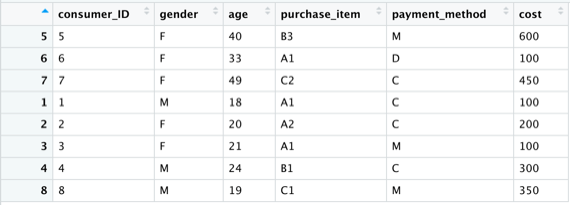
1.其中使用rbind()函式時,需要注意對應欄位變數名稱,否則將無法進行合併:
new_consumer <- rbind(consumer_old,consumer_young)
#使用rbind()函式,將欲合併的兩筆資料框依序放入函式中
View(new_consumer)
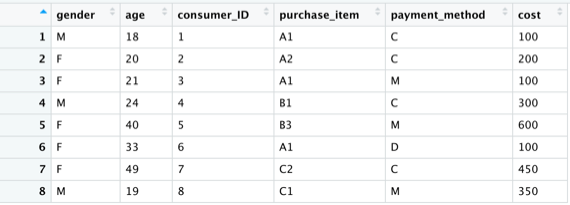
2.使用cbind()函式時,可以用來新增變數到原始資料框中,不需要對應欄位變數名稱:
#首先我們再次創建兩種資料框(一是消費者年齡和性別、二是其餘資料)
c1 <-
data.frame(gender=c(‘M’,’F’,’F’,’M’,’F’,’F’,’F’,’M’),
age = c(18,20,21,24,40,33,49,19))
c2 <-
data.frame(consumer_ID = c(1,2,3,4,5,6,7,8),
purchase_item=c(‘A1′,’A2′,’A1′,’B1′,’B3′,’A1′,’C2′,’C1’),
payment_method=c(“C”,”C”,”M”,”C”,”M”,”D”,”C”,”M”),
cost=c(100,200,100,300,600,100,450,350))
#接著使用cbind()函式將兩資料框進行合併
new_consumer <- cbind(c1,c2)
#將欲合併的資料框依序放入cbind()函式中
View(new_consumer)
這樣是否了解使用rbind()函式和cbind()函式在使用上的差異了呢,因此再遇到不同情況時,記得要選擇對的合併方式,才不會出現error喔!
另外還有一個函數merge()也能夠用做合併資料,個人認為是一個功能較為整合的一個函式。
3.使用函數merge(),可以依據兩資料框裡某個相同變數,將兩筆資料進行合併處理:
#首先我們再次創建兩種資料框(一是消費者年齡和性別、二是其餘資料,但兩資料框都具備有消費者ID)
c1 <-
data.frame(consumer_ID = c(1,2,3,4,5,6,7,8,9),
gender=c(‘M’,’F’,’F’,’M’,’F’,’F’,’F’,’M’,’M’),
age = c(18,20,21,24,40,33,49,19,20))
c2 <-
data.frame(consumer_ID = c(1,2,3,4,5,6,7,8,10), purchase_item=c(‘A1′,’A2′,’A1′,’B1′,’B3′,’A1′,’C2′,’C1′,’C3’),
payment_method=c(“C”,”C”,”M”,”C”,”M”,”D”,”C”,”M”,”C”), cost=c(100,200,100,300,600,100,450,350),400)
#特別注意,這裡故意將consumer_ID欄位設置成有差異(9,10)
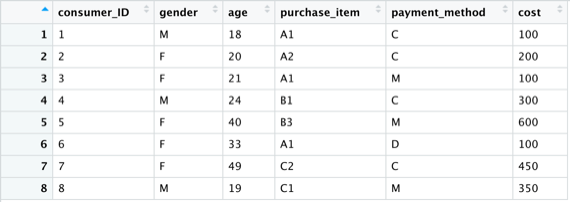
#接著利用merge()函式,將具備consumer_ID欄位的兩資料框進行合併
new_consumer <- merge(c1,c2,by=”consumer_ID”)
View(new_consumer)
#完成合併並顯示出consumer_ID欄位且有相同ID的消費者(1~8)所有資料
#因故意將consumer_ID設置兩碼不一樣(9,10),可以透過all = T(詢問是否觀察所有資料),來看編號9和10什麼資料是空缺的。
new_consumer <- merge(c1,c2,by=”consumer_ID”,all = T)
View(new_consumer)
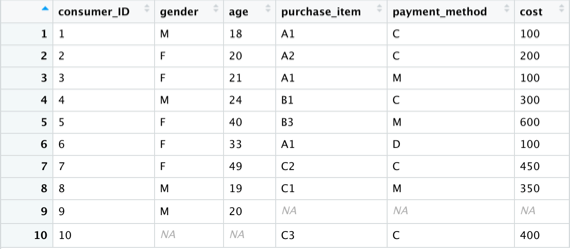
*總結以上,資料分割與合併是資料預處理階段相當重要的環節,同學們應了解每個函數的使用方法以及使用限制,未來拿到多筆資料時,才能得心應手。
以上便是如何使用R語言進行資料分割與合併,若您覺得有幫助的話,再請幫我們留個好評,謝謝您的觀看,我們下次見。

封面圖-500x383.png)

